

強化学習やバンディットアルゴリズムにおいて、「探索」と「活用」のバランスを取ることは非常に重要です。
その中でも、より理論的に優れた手法として知られているのが**UCB方策(Upper Confidence Bound policy)**です。
本記事では、UCB方策の仕組みや考え方、ε-greedyとの違い、実務での活用ポイントまでをわかりやすく解説します。
UCB方策とは
UCB方策とは、過去の実績(報酬)と「まだ十分に試されていない不確実性」の両方を考慮して行動を選択する手法です。
基本の考え方
- 平均的に報酬が高い行動は優先する
- まだあまり試していない行動も積極的に試す
この2つを同時に満たすことで、探索と活用のバランスを自動的に調整します。
強化学習における課題:探索と活用
強化学習では、以下の2つの行動のバランスが重要です。
探索(Exploration)
- 未知の行動を試す
- より良い選択肢を見つける
活用(Exploitation)
- 既に高い成果が出ている行動を選ぶ
- 安定した報酬を得る
このバランスを誤ると、学習効率が大きく低下します。
UCB方策の仕組み
UCB方策では、各行動に対して「UCBスコア」と呼ばれる指標を計算し、その値が最大となる行動を選択します。
UCBスコアのイメージ
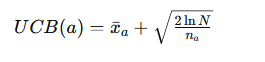
各要素の意味
- xˉa\bar{x}_a:行動aの平均報酬(これまでの成果)
- nan_a:行動aを選択した回数
- NN:全体の試行回数
- ln:自然対数
重要なポイント
この式は、以下の2つの要素で構成されています。
① 平均報酬(活用)
- 成績が良い行動ほど高く評価される
② ボーナス項(探索)
- 試行回数が少ない行動ほど値が大きくなる
- 未探索の選択肢を優先する仕組み
つまり、「よく当たるが未検証な選択肢」を自然に優先する設計になっています。
ε-greedy方策との違い
UCB方策は、ε-greedyとよく比較されます。
| 項目 | UCB方策 | ε-greedy方策 |
|---|---|---|
| 探索方法 | 不確実性に基づく | ランダム |
| 行動選択 | 理論的に最適に近い | シンプル |
| 効率性 | 高い | やや低い |
| 実装難易度 | やや高い | 低い |
イメージの違い
- ε-greedy:ランダムに試す
- UCB:意味のある探索を行う
UCB方策のメリット
効率的な探索
無駄なランダム探索を減らし、効率的に最適解へ近づきます。
自動的なバランス調整
探索と活用のバランスを手動で調整する必要が少なくなります。
理論的な裏付け
収束性や性能に関する理論が確立されているため、信頼性が高い手法です。
注意点・デメリット
実装がやや複雑
ε-greedyと比べると、計算や管理が少し複雑になります。
初期段階の不安定さ
試行回数が少ないうちは、ボーナス項の影響が大きくなりやすいです。
状況変化への対応
環境が頻繁に変わる場合は、別の手法(例:割引やスライディングウィンドウ)が必要になることがあります。
活用事例
UCB方策は、実務でも多くの分野で活用されています。
Web広告の最適化
- クリック率の高い広告を優先
- 新しい広告も効率的にテスト
レコメンドシステム
- 人気コンテンツを表示しつつ
- 未評価コンテンツも適切に露出
A/Bテストの高度化
- 成果に応じて配信比率を動的に変更
- テスト期間の短縮
日本企業での活用ポイント
実務で導入する際には、以下を意識すると効果的です。
- 初期データが少ない場合は簡易手法と併用する
- KPI(CTR、CVRなど)を明確に定義する
- データ更新頻度に応じてアルゴリズムを調整する
まとめ
UCB方策は、探索と活用のバランスを理論的に最適化する優れた手法です。
ポイントを整理すると:
- 平均報酬+不確実性(ボーナス)で行動を評価
- 試行回数が少ない選択肢を自然に優先
- ε-greedyより効率的な探索が可能
- 広告・レコメンド・A/Bテストなどで活用
強化学習やデータドリブンな意思決定を高度化したい場合、UCB方策は非常に有力な選択肢となります。
シンプルな手法から一歩進んだアルゴリズムとして、ぜひ理解しておきたい重要な概念です。
こちらもご覧ください:ε-greedy方策とは?探索と活用を両立するシンプル戦略をわかりやすく解説


