

機械学習やディープラーニングでは、モデルの精度を高めるために大量のデータを学習させます。
しかし、モデルを複雑にしすぎると、「学習データだけには非常に強いが、新しいデータには弱い」という問題が発生することがあります。
この問題は「過学習(Overfitting)」と呼ばれ、実際のAI開発で非常に重要な課題です。
そこで活用されるのが「正則化(Regularization)」です。
正則化は、モデルが過度に複雑になるのを防ぎ、未知データにも強い汎化性能を持たせるための技術です。
本記事では、正則化の基本概念から、L1正則化・L2正則化の違い、ドロップアウトとの関係、実際の活用例までをわかりやすく解説します。
正則化とは?
正則化とは、機械学習モデルが複雑になりすぎるのを防ぐための手法です。
AIモデルは、学習を進めるほど訓練データへ適合していきます。
しかし、適合しすぎると、
- ノイズ
- 偶然の偏り
- 外れ値
まで学習してしまいます。
その結果、本番環境の未知データに対する予測性能が低下します。
これが「過学習」です。
過学習(Overfitting)とは?
過学習とは、モデルが学習データを“覚えすぎてしまう”状態です。
具体例
たとえば、試験対策を考えてみましょう。
- 問題のパターンを理解している → 応用問題にも対応できる
- 過去問を丸暗記しただけ → 少し形式が変わると解けない
過学習したAIは、後者の状態に近くなります。
過学習が起きる原因
主な原因には以下があります。
- モデルが複雑すぎる
- パラメータ数が多すぎる
- 学習データが少ない
- ノイズを学習している
特に深層学習では、巨大モデルほど過学習リスクが高まります。
正則化は何をしているのか?
正則化では、モデルの「複雑さ」にペナルティを与えます。
一般的には、損失関数へ「正則化項」を追加します。
正則化付き損失関数
基本的なイメージは以下です。

を表します。
なぜ効果があるのか?
正則化によって、
- 極端な重み
- 不要な複雑性
を抑制できます。
その結果、
- シンプル
- 安定的
- 汎化性能が高い
モデルを作りやすくなります。
L1正則化とは?
L1正則化は、パラメータの絶対値にペナルティを与える方法です。
![]()
L1正則化の特徴
L1正則化では、一部の重みが0になりやすい特徴があります。
つまり、不要な特徴量を自動的に無効化できるのです。
特徴量選択に強い
そのため、L1正則化には「特徴量選択」の効果があります。
大量の特徴量がある場合に、
- 重要な特徴だけ残す
- 不要な特徴を削減する
用途で活躍します。
ラッソ回帰(Lasso Regression)
回帰分析でL1正則化を使ったものを「ラッソ回帰」と呼びます。
特に、
- 高次元データ
- 不要変数が多いケース
で有効です。
L2正則化とは?
L2正則化は、パラメータの二乗和へペナルティを与える方法です。
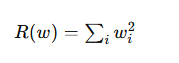
L2正則化の特徴
L2正則化では、
- 重みを完全にゼロにはしない
- 極端に大きい値を抑える
特徴があります。
そのため、モデル全体を滑らかで安定した状態へ導きます。
リッジ回帰(Ridge Regression)
回帰分析でL2正則化を適用したものを「リッジ回帰」と呼びます。
多くの実務モデルで標準的に利用されています。
L1正則化とL2正則化の違い
L1正則化
- 重みを0にしやすい
- 特徴量削減に向く
- スパースなモデルを作る
L2正則化
- 重み全体を滑らかに抑制
- 安定性が高い
- 深層学習で広く利用
どちらを選ぶべき?
用途によって異なります。
L1が向くケース
- 特徴量が非常に多い
- 不要特徴を削減したい
L2が向くケース
- 安定性重視
- 一般的な深層学習
実務では両者を組み合わせた「Elastic Net」もよく利用されます。
ドロップアウト(Dropout)とは?
ニューラルネットワークでは、「Dropout(ドロップアウト)」も代表的な正則化手法です。
ドロップアウトの仕組み
学習中、一部のノードをランダムに無効化します。
イメージとしては、「毎回少し違うネットワークで学習する」ような状態です。
なぜ効果がある?
特定ノードへの依存を防げるため、
- 過学習を抑制
- 汎化性能向上
につながります。
深層学習では非常に一般的な技術です。
正則化が重要な理由
現代AIは巨大化が進んでいます。
特に、
- 大規模言語モデル(LLM)
- 画像生成AI
- 音声認識
などでは、膨大なパラメータを扱います。
そのため、正則化なしでは、
- 過学習
- 学習不安定
- 汎化性能低下
が起こりやすくなります。
正則化は、現代AIの安定運用に不可欠な技術と言えます。
正則化の注意点
強すぎる正則化
正則化を強くしすぎると、
- モデルが単純になりすぎる
- 学習不足(Underfitting)
になる場合があります。
ハイパーパラメータ調整が必要
正則化強度 λ\lambda の設定は非常に重要です。
適切な値を探すために、
- 検証データ
- グリッドサーチ
- ベイズ最適化
などが使われます。
まとめ
正則化(Regularization)とは、機械学習モデルの複雑さへペナルティを与え、過学習を防ぐ技術です。
代表的な手法には、
- L1正則化
- L2正則化
- Dropout
などがあります。
また、
- L1 → 特徴量選択
- L2 → モデル安定化
という違いも重要です。
現代AIでは、モデルの巨大化に伴い「汎化性能」がますます重要になっており、正則化は高性能AIを支える基盤技術の一つとなっています。
こちらもご覧ください:KLダイバージェンス(カルバック・ライブラー情報量)とは?機械学習で重要な確率分布の違いを解説


