
決定木(デシジョンツリー)は、分類や予測などの意思決定に使用される分析手法です。
この手法は、各ノードで条件を評価しながら進み、最終的な結果にたどり着くツリー構造を持ち、データ分析や機械学習での用途が幅広いのが特徴です。
本記事では、決定木の基本的な仕組みから実際の活用方法までを詳しく解説し、データ活用の視点からその価値を探ります。
決定木の基礎概念と構造
決定木とは?
決定木は、分類や予測を行うための**木構造(ツリー構造)**を利用した手法で、各分岐(ノード)で条件を評価し、条件に沿って次の分岐に進んでいくことで結果にたどり着きます。
この構造により、決定木は視覚的に分かりやすく、複雑なデータを整理して分類するのに適しています。
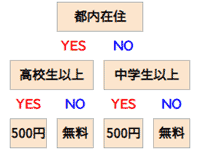
決定木の構成要素
- ルートノード: 決定木の出発点で、最初に評価される条件を表します。
- 内部ノード: 条件分岐の途中に位置し、評価された条件に基づき次の枝に進むポイントです。
- リーフノード: 最終的な結論やクラス分類が示される部分で、ここに到達するまでの条件が分類結果に直接影響します。
分類木と回帰木
- 分類木(classification tree): データをクラスに分類することを目的とし、スパムメールの判別や診断支援などの用途に適しています。
- 回帰木(regression tree): 連続値の予測に使用され、例えば不動産価格の予測や売上予測といった、数値の近似に適用されます。
機械学習における決定木の活用
決定木学習のメリット
- 説明性が高い: なぜその結果になったのかを視覚的に説明しやすいため、データの理解やモデルの透明性が重要な場面で効果的です。
- 非線形データへの適応: データの構造が複雑であっても対応でき、質的変数や量的変数を組み合わせて扱えます。
- 外れ値に強い: 決定木は外れ値の影響が小さく、異常値の多いデータに対しても安定して処理が可能です。
決定木の活用例
- 医療分野: 病気の診断支援システムにおいて、症状や検査結果に基づく分類木を使って診断のサポートを行います。
- マーケティング: 顧客の購買行動を分類し、適切なプロモーションを提供するためのツールとして利用されます。
- 金融業界: リスク評価や融資審査において、データに基づいた分類を行うことで、精度の高い意思決定をサポートします。
注意点と限界
決定木は汎用性の高い手法ですが、いくつかの注意点があります。
- 過学習のリスク: 特に大きな決定木は、特定のデータに過度に適応しやすく、新しいデータに対して精度が落ちることがあります。
- 線形データへの不向き: データが線形の場合、他の回帰分析などの手法の方が精度が高い場合も多いため、決定木は適切ではないことがあります。
決定木の構築方法
決定木を構築するアルゴリズム
決定木を作成する際に一般的に使用されるアルゴリズムには以下のようなものがあります。
- ID3アルゴリズム: エントロピーと情報利得を用いて分岐条件を設定し、最も情報量が多い分岐を選択していく方法です。
- C4.5アルゴリズム: ID3の改良版で、連続値も扱えるのが特徴です。
- CART(分類・回帰木): 回帰木の作成も行えるアルゴリズムで、Gini係数を使って分岐を決定します。
決定木の評価指標
構築された決定木の評価には、以下の指標が用いられます。
- 正確率: 正しく分類できたデータの割合を示します。
- 再現率: 実際に該当するデータの中でどれだけ正しく分類されたかを示す指標です。
- F1スコア: 正確率と再現率の調和平均をとったもので、モデルの精度をバランスよく評価できます。
まとめ
決定木は、視覚的で分かりやすい構造を持つデータ分析手法で、分類や予測に幅広く使用されています。
ビジネスや医療、マーケティングなど、多くの分野で活用され、データの解釈をサポートします。
さらに、機械学習での決定木学習により、非線形データにも対応しやすく、モデルの透明性が求められる場面での適用が期待できます。
ただし、過学習や線形データへの適用には注意が必要で、データの特徴に合わせた適切なアルゴリズム選択が重要です。
さらに参照してください:
システム開発で役立つデシジョンテーブルとは?基本から応用まで徹底解説
Visited 11 times, 1 visit(s) today