

ディープラーニングや機械学習で使われるニューラルネットワークは、画像認識や自然言語処理など、複雑な問題を高精度で解決できることで知られています。
その性能を支えている重要な要素の一つが、「活性化関数(Activation Function)」です。
活性化関数は、ニューラルネットワークに“非線形性”を与える役割を持ちます。
もし活性化関数が存在しなければ、どれだけ層を深くしても単純な線形計算しかできず、複雑なパターンを学習できません。
本記事では、活性化関数の基本的な役割から、代表的な種類、ReLUが主流になった理由、シグモイド関数やtanh関数との違いまで、初心者にもわかりやすく解説します。
活性化関数とは?
活性化関数(Activation Function)とは、ニューラルネットワークの各ニューロンで入力値に対して非線形変換を行う関数です。
簡単に言えば、「AIが複雑な判断をできるようにする仕組み」と言えます。
ニューラルネットワークの基本構造
人工ニューラルネットワーク(ANN)は、人間の脳の神経細胞(ニューロン)を模して作られています。
各ニューロンは、
- 複数の入力を受け取り
- 重み付けして加算し
- 次の層へ出力
します。
ニューロンの計算イメージ
ニューラルネットワークでは、まず入力値の加重和を計算します。

を表します。
なぜ活性化関数が必要なのか?
もしニューラルネットワークが、
- 加算
- 実数倍
だけを繰り返していた場合、全体としては単なる線形変換になります。
つまり、「層を深くしても意味がない」状態になります。
線形変換だけでは限界がある
現実世界のデータは非常に複雑です。
たとえば画像認識では、
- 曲線
- 模様
- 陰影
- 複雑な形状
を理解する必要があります。
これらは単純な直線関係では表現できません。
非線形性が重要
そこで必要になるのが、「非線形変換」です。
活性化関数は、ニューラルネットワークへ非線形性を導入し、複雑なパターン学習を可能にします。
活性化関数の役割
活性化関数には、主に以下の役割があります。
- 非線形性の導入
- 複雑な特徴抽出
- 表現力向上
- 深層学習の成立
特にディープラーニングでは不可欠な存在です。
初期の活性化関数:ステップ関数
ニューラルネットワーク初期研究では、「ステップ関数」が使われていました。
ステップ関数とは?
一定の閾値(しきい値)を超えると1、超えなければ0を出力する関数です。
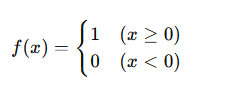
これは脳のニューロンの「発火」を模したものです。
ステップ関数の問題点
ステップ関数には、微分できないという問題があります。
なぜ微分が重要?
ニューラルネットワークでは、誤差逆伝播法(Backpropagation)を使って学習します。
この学習では、
- 微分
- 勾配計算
が必要になります。
そのため、滑らかに微分可能な関数が求められるようになりました。
シグモイド関数(Sigmoid Function)
そこで登場したのが「シグモイド関数」です。
シグモイド関数の特徴
シグモイド関数は、出力を0〜1へ滑らかに変換します。
メリット
- 微分可能
- 確率として解釈しやすい
- 出力が滑らか
デメリット
一方で、勾配消失問題(Gradient Vanishing)が起こりやすい欠点があります。
入力が大きくなると勾配が極端に小さくなり、深いネットワークで学習しづらくなります。
tanh関数とは?
シグモイド関数を改良したものが「tanh関数(双曲線正接関数)」です。
tanh関数の特徴
出力範囲は、-1〜1になります。
シグモイドとの違い
tanh関数は、出力が0中心になるため、学習効率が改善される場合があります。
しかし、勾配消失問題は依然として残ります。
ReLU(Rectified Linear Unit)とは?
現在、最も広く利用されている活性化関数が「ReLU」です。
ReLUの数式
ReLUは非常にシンプルです。
![]()
ReLUの特徴
- 負値は0
- 正値はそのまま出力
します。
なぜReLUが主流なのか?
ReLUには多くのメリットがあります。
計算が軽い
単純な比較だけなので高速です。
勾配消失が起きにくい
正の領域では勾配が一定のため、深層学習でも学習しやすくなります。
深いネットワークに強い
現在のディープラーニング革命を支えた重要技術の一つです。
ReLUの欠点
一方で、負値領域で勾配が0になる問題があります。
これを「Dead ReLU問題」と呼びます。
改良版ReLUも存在する
この問題を改善するため、
- Leaky ReLU
- PReLU
- ELU
- GELU
など、多くの派生関数が提案されています。
特にTransformer系では「GELU」がよく使われています。
ソフトプラス(Softplus)とは?
Softplusは、ReLUを滑らかにした関数です。
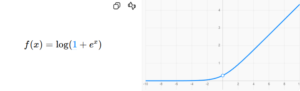
Softplusの特徴
- ReLUより滑らか
- 微分可能
- 勾配が安定
という特徴があります。
ただし計算コストはやや高くなります。
活性化関数はどこで使われる?
活性化関数は、あらゆる深層学習モデルで使われています。
主な利用分野
- 画像認識
- 音声認識
- 自然言語処理
- 生成AI
- 大規模言語モデル(LLM)
などです。
Transformerでは何が使われる?
近年のTransformer系モデルでは、
- ReLU
- GELU
が特によく使われています。
ChatGPTのようなLLMでも重要な役割を担っています。
まとめ
活性化関数(Activation Function)とは、ニューラルネットワークに非線形性を与える重要な仕組みです。
もし活性化関数がなければ、深層学習は単なる線形変換となり、複雑な問題を解けません。
代表的な活性化関数には、
- ステップ関数
- シグモイド関数
- tanh関数
- ReLU
- Softplus
などがあります。
現在では、ReLU系関数がディープラーニングの主流となっており、画像認識や生成AI、大規模言語モデルなど、現代AI技術の中核を支えています。
こちらもご覧ください:ドロップアウト(Dropout)とは?過学習を防ぐ深層学習の代表的な正則化手法を解説


