
過学習(overtraining)は、機械学習や回帰分析の分野で頻繁に発生する現象で、学習データに対して過剰に適合しすぎることを指します。
この現象は、モデルが本来のデータの傾向を無視し、外れ値やノイズにまで忠実に再現してしまう結果を引き起こします。
本記事では、過学習の詳細なメカニズム、影響、そしてその対策について詳しく解説します。
過学習の基本概念
過学習の定義
過学習は、学習データに対してモデルが非常に忠実に適合することで、未知のデータに対しては適切な予測ができなくなる現象です。
この場合、モデルの回帰曲線は学習データのほとんどの点を通る複雑な形状となり、実際の応用では無意味な結果を生み出します。
過学習が発生する原因
1.モデルの自由度の増加: 回帰問題において、予測精度を高めるために媒介変数を増やしたり、複雑なモデルを使用することが一般的です。
しかし、データの規模に対して詳細すぎるモデルを用意すると、外れ値やノイズも適切にモデル化されてしまいます。
2.データの偏り: 学習データに偏りがあると、モデルはその偏りを反映し、一般的な傾向を無視してしまうことがあります。
過学習の影響
過学習が発生すると、モデルは以下のような問題を引き起こします。
知らないデータに対する無能さ
過学習したモデルは、学習データに対しては完璧に適合するものの、未知のデータに対しては予測精度が低下します。
このため、実際のデータに基づいた予測ができず、実用的ではなくなります。
ビジネスへの影響
ビジネスにおいて過学習は、マーケティング分析や顧客予測などにおいて大きな損失をもたらす可能性があります。
例えば、過学習したモデルに基づいて行った戦略が実際の市場では通用しないことが多々あります。
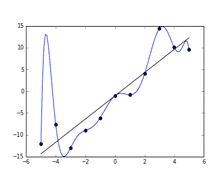
過学習を防ぐための対策
データの増加
学習データを増やすことは、過学習を防ぐ最も効果的な方法の一つです。
より多くのデータを用いることで、モデルがデータの真の傾向を学習しやすくなります。
モデルの単純化
モデルの自由度を意図的に下げ、単純なモデルを使用することも有効です。
単純なモデルは、外れ値やノイズの影響を受けにくいため、過学習のリスクを減らすことができます。
交差検証
「交差検証」は、学習データを2つに分け、一方で学習し、もう一方で精度の検証を行う手法です。
この方法を用いることで、モデルの汎用性を確認できます。
正則化
「正則化」は、モデルが複雑化するとペナルティを与える技法です。
これにより、モデルが過剰に適合するのを防ぎ、より一般的な傾向を捉えられるようになります。
まとめ
過学習は、機械学習や回帰分析において非常に重要な概念です。
モデルが学習データに過剰に適合することで、未知のデータに対する予測が無効になるため、ビジネスや研究においては特に注意が必要です。
過学習を防ぐためには、データの増加、モデルの単純化、交差検証、正則化といった対策を講じることが求められます。
正しいアプローチを取ることで、より信頼性の高いモデルを構築することができるでしょう。