
過学習(オーバートレーニング、英: Overfitting)は、機械学習や回帰分析において、モデルが学習データに対して過剰に適合し、実際の傾向を反映しなくなる現象です。
この記事では、過学習の原因、影響、および対策方法について詳しく解説します。
過学習(オーバートレーニング)とは?
過学習の定義
過学習(オーバートレーニング、Overfitting)とは、学習データに対してモデルが過剰に適合することで、データが本来示唆する傾向から大きく外れてしまう現象です。
これは、回帰分析や機械学習のモデルが、データの外れ値やノイズまでも再現してしまうことによって発生します。
過学習の原因
過学習が発生する主な原因は以下の通りです:
- モデルの自由度が高すぎる: モデルが複雑すぎると、学習データのすべての細部やノイズまで再現してしまう可能性があります。
- データ量が不足している: 学習データが少ない場合、モデルがデータの特異性に適応しすぎて、一般的な傾向を捉えられなくなることがあります。
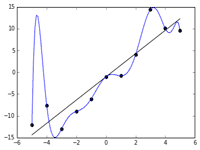
過学習の影響
モデルの適用性の低下
過学習を起こしたモデルは、学習データには非常に適合するものの、未知のデータに対しては不正確な予測をすることが多いです。
これは、モデルが学習データの特異な特徴やノイズを過度に反映してしまうためです。
回帰曲線の複雑化
過学習が発生すると、回帰曲線が複雑に折れ曲がり、学習データのほとんどの点を通るようになります。
しかし、この曲線は新しいデータに対しては適切に予測できないことが多いです。
過学習の対策方法
学習データの増加
学習データを増やすことで、モデルがより多くのパターンを学習し、ノイズや外れ値の影響を軽減することができます。
モデルの簡素化
モデルの自由度を意図的に下げることで、過学習を防ぐことができます。
具体的には、より単純なモデルを使用することで、一般的な傾向を捉えやすくなります。
交差検証の実施
データをトレーニングセットとテストセットに分け、交差検証を行うことで、モデルの精度を検証し、過学習を検出することができます。
正則化の利用
正則化(Regularization)は、モデルが複雑になることを防ぐために、モデルの複雑さにペナルティを与える技法です。
これにより、モデルが学習データに過度に適合するのを防ぎます。
まとめ
過学習は、学習データに対してモデルが過剰に適合し、未知のデータに対して不正確な予測を行う現象です。
過学習を防ぐためには、学習データの増加、モデルの簡素化、交差検証、正則化などの対策を講じることが重要です。
これにより、モデルの精度を向上させ、実務での使用において信頼性の高い結果を得ることができます。