
過学習(overtraining)、または過剰適合(overfitting)は、回帰分析や機械学習における重要な問題です。
これは、モデルが学習データに対して過度に適合しすぎて、実際のデータが示す傾向から大きく逸脱してしまう現象です。
本記事では、過学習の原因、影響、そしてこれを防ぐための対策について詳しく解説します。
過学習の基本概念
過学習の定義
過学習(overtraining)とは、機械学習モデルが訓練データに対して過剰に適合しすぎることで、未知のデータに対しては性能が劣る状態を指します。
具体的には、モデルが訓練データのノイズや外れ値まで忠実に学習してしまい、データが本来示すべき傾向を捉えられなくなる現象です。
過学習の影響
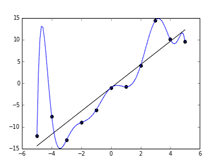
過学習が発生すると、モデルの回帰曲線は学習データのほとんどの点を通過するように複雑に折れ曲がります。
その結果、学習データには完全に適合しますが、未知のデータに対しては的外れな予測を行い、実際の利用には適さない状態になります。
過学習の原因
モデルの複雑さ
過学習の主な原因は、モデルの自由度が高すぎることです。
例えば、回帰問題において多くの媒介変数や複雑な関数を用いると、学習データに対する適合度が高まりますが、外れ値やノイズまで学習してしまうことになります。
これにより、モデルが実際のデータの傾向を捉えにくくなります。
データの不足
学習データの量が不足していると、モデルは少ないデータに過度に依存してしまい、ノイズや外れ値の影響を受けやすくなります。
このため、訓練データには適合するものの、未知のデータに対しては性能が低下します。
過学習の対策
データの増加
学習データを増やすことで、モデルがより多くのパターンを学習し、過学習のリスクを低減できます。
データが増えることで、ノイズや外れ値の影響が相対的に小さくなり、モデルの一般化能力が向上します。
モデルの単純化
モデルの複雑さを減らすことも、過学習を防ぐための有効な手段です。
例えば、媒介変数を減らす、またはより単純なモデルを選択することで、モデルが訓練データに過度に適合するのを防ぐことができます。
交差検証
交差検証(cross-validation)とは、学習データを複数の部分に分け、一部でモデルの学習を行い、残りの部分で評価を行う方法です。
これにより、モデルが未知のデータに対しても良好な性能を示すかどうかを確認できます。
正則化
正則化(regularization)とは、モデルの複雑さにペナルティを与える手法です。
これにより、過度に複雑なモデルが構築されるのを防ぎ、過学習のリスクを低減します。
代表的な正則化手法には、L1正則化やL2正則化があります。
まとめ
過学習(overtraining)とは、機械学習モデルが学習データに過剰に適合しすぎて、未知のデータに対して性能が低下する現象です。
これを防ぐためには、データの増加、モデルの単純化、交差検証、正則化などの対策が有効です。
適切な対策を講じることで、モデルの一般化能力を高め、より信頼性の高い予測を行うことができます。
さらに参考してください。