
ハッシュ結合(hash join)は、リレーショナルデータベース(RDB)において、大規模データの結合処理における高速化手法の一つです。
JOIN操作はSQLクエリの中でも頻繁に使われるため、パフォーマンスの最適化にはそのアルゴリズム理解が重要です。
本記事では、ハッシュ結合の仕組み、適用条件、他のJOINアルゴリズムとの違い、そして実際の活用例まで、ITエンジニア視点で詳しく解説します。
ハッシュ結合とは?
ハッシュ結合の基本概念
ハッシュ結合とは、RDBにおけるテーブル結合時に使用される等価条件に特化したJOINアルゴリズムです。
主に以下のような特徴があります。
-
一方のテーブル(通常は小さい方)を基にハッシュテーブル(インメモリ)を構築
-
他方のテーブルを順に走査し、対応するハッシュ値をもとに一致する行を探す
-
ソート処理が不要なため、等価条件において非常に高速に動作
主な利用シーン
-
結合条件が
=(等号)で指定されている場合 -
結合対象の一方のテーブルがメモリに収まる程度に小さい
-
インデックスがなくても高速な結合が求められる場面
ハッシュ結合の処理手順
ビルドフェーズ(Build Phase)
まず、一方のテーブル(一般的には行数が少ない方)を使用し、結合キーに基づいてハッシュテーブルを構築します。
各レコードのキーに対してハッシュ関数を適用し、ハッシュ値ごとにデータを分類・格納します。
プローブフェーズ(Probe Phase)
次に、もう一方のテーブルを先頭から順に走査し、同様にハッシュ値を算出して、先に構築したハッシュテーブルから一致するレコードを探索・結合します。
図解イメージ(例)
以下は簡易的な例です:

-
customersテーブルからハッシュテーブルを作成 -
ordersテーブルの各行に対しcustomer_idのハッシュ値を算出して照合 -
一致する場合に
JOIN結果を生成
他の結合方式との違い
ネステッドループ結合(Nested Loop Join)との比較
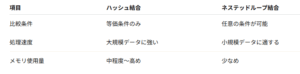
ソートマージ結合(Sort Merge Join)との比較
ハッシュ結合はソート不要かつ等価条件に特化しているため、JOIN条件が=のみで、ソートコストを避けたい場合に最適です。
一方で、<や>などの比較演算子を含む場合は、ソートマージ結合の方が適しています。
パフォーマンス最適化における注意点
メモリ使用量とスケーラビリティ
ハッシュ結合では、ハッシュテーブルをメモリ上に構築するため、メモリ不足が発生するとディスクI/Oによりパフォーマンスが低下する恐れがあります。
そのため、結合対象のテーブルサイズやRDBMSの設定を事前に確認しておくことが重要です。
RDBMSによる実装差異
PostgreSQL、Oracle、MySQL(特にInnoDB)、SQL Serverなど、各RDBMSにおいてハッシュ結合の実装や最適化条件は異なるため、実際の利用時は実行計画(EXPLAINなど)を確認しながらチューニングを行うことが求められます。
ハッシュ結合が使われる実例
ビッグデータ分析基盤におけるJOIN最適化
大規模なログデータをJOINして分析する際、インデックスのない列での等価JOIN処理が必要になる場合にハッシュ結合が活躍します。
-
例:広告ログ × ユーザー情報 のJOIN
-
毎日億単位のレコードが生成される場合でも、ハッシュテーブルによって高速処理が可能
ETL処理における結合処理
ETLツールやDWH系処理(例:BigQuery, Redshift)でも、ハッシュ結合は頻繁に利用され、特にパーティションやシャーディング構成でも有効です。
まとめ
ハッシュ結合(hash join)は、SQLにおける等価結合のパフォーマンスを最大化するための非常に強力なアルゴリズムです。
本記事のポイントを振り返ります:
-
等価条件 (
=) に最適化された結合アルゴリズム -
メモリ上にハッシュテーブルを構築することで高速な探索が可能
-
小さなテーブルと大きなテーブルのJOIN処理に特に効果的
-
ネステッドループやソートマージ結合との使い分けが重要
-
RDBMSやデータ量、条件に応じた戦略的な選定がパフォーマンス改善の鍵
SQLパフォーマンスチューニングを行うエンジニアにとって、ハッシュ結合の理解と活用は避けて通れない知識です。
今後のシステム開発や運用に役立ててください。