
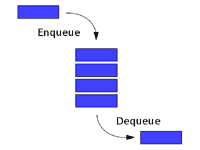
エンキュー(enqueue)とデキュー(dequeue)は、データ構造の一種であるキュー(queue)において、要素を追加したり取り出したりするための重要な操作です。
キューは「先入れ先出し」(FIFO)という原則に基づいており、エンキューによって新しい要素が末尾に追加され、デキューによって先頭の要素が取り出されます。
本記事では、エンキューとデキューの概念、操作の流れ、具体的な実装方法について詳しく解説します。
エンキューとデキューの基本
1. キューの定義
キューは、データを一列に並べるデータ構造で、主にタスクやリクエストの順序を管理するために使用されます。
キューの基本的な特性は、最も古い要素が最初に取り出されることです。
この性質により、エンキューとデキューは効率的なデータ処理において欠かせない操作となります。
2. エンキュー(enqueue)
エンキューとは、キューの末尾に新しい要素を追加する操作を指します。
この操作によって、キューの要素数が1つ増え、追加された要素は最も後に処理されることになります。
例えば、タスク管理システムにおいて、新しいタスクが発生した際にエンキューを行うことで、そのタスクが処理されるのは、既存のタスクの後になるということです。
3. デキュー(dequeue)
デキューとは、キューの先頭から要素を取り出し、削除する操作を指します。
この操作によって、キューの要素数が1つ減り、次に先頭になるのは元々先頭の次にあった要素です。
例えば、顧客サービスにおいて、最初に並んでいた顧客がサービスを受けた場合、デキューを行うことで次の顧客が前に進むことになります。
エンキューとデキューの実装
1. 配列を使用した実装
配列を用いてキューを実装する場合、エンキューとデキューの操作は以下のように行われます。
- エンキュー
新しい要素を配列の末尾に追加します。
配列のインデックスを1つ増やし、要素数をカウントします。
- デキュー
配列の先頭から要素を削除し、次の要素を新しい先頭として設定します。
全ての要素を前に移動させるのは非効率的なため、現在の先頭と末尾のインデックスを管理します。
2. リンクリストを使用した実装
リンクリストを使用した場合、エンキューとデキューの操作はさらに効率的になります。
各要素はノードとして扱われ、エンキューは新しいノードを末尾に追加し、デキューは先頭のノードを削除するだけで済みます。
この方法は、特に多くの要素を扱う場合に優れたパフォーマンスを発揮します。
エンキューとデキューの応用例
1. プリンタースプーリング
プリンタースプーリングでは、印刷ジョブがキューにエンキューされ、デキューによって順番に印刷されます。
これにより、複数の印刷リクエストを効率的に処理することができます。
2. バックグラウンドタスク処理
サーバーやアプリケーションでのバックグラウンドタスクは、キューを使用して管理されることが多いです。
タスクはエンキューされ、デキューによって順番に処理されるため、タスクの効率的な管理が可能となります。
まとめ
エンキューとデキューは、キューというデータ構造において要素を効率的に出し入れするための基本的な操作です。
これらの操作は、さまざまなアプリケーションやシステムで広く利用されており、特にタスク管理やデータ処理において重要な役割を果たします。
エンキューとデキューの理解は、プログラミングやデータ構造の学習において非常に有益です。
