機械可読(machine readable)という概念は、デジタルデータがコンピュータによって簡単に処理できる状態を指します。
この特性により、データの集計や変換が容易に行えるため、現代のデータ管理や分析において不可欠な要素となっています。
本記事では、機械可読データの定義、代表的なフォーマット、そしてそれらがどのように活用されるのかについて詳しく解説します。
機械可読データの基本概念
機械可読とは?
機械可読データとは、コンピュータプログラムによって簡単に読み取ることができ、処理や解析が行える形式のデータです。
たとえば、数値を手書きで記入した画像データは、人間にとっては理解可能ですが、コンピュータにとっては認識するのが難しく、精度も低くなりがちです。
一方、テキストデータであれば、単純なルールに基づいて処理することで、データを効率的に扱うことができます。
代表的な機械可読フォーマット
CSV(Comma-Separated Values)
CSV形式は、データをカンマで区切ったテキストファイルで、最も基本的な機械可読形式の一つです。
例えば、次のようなデータがCSV形式で保存されているとします:

この形式では、改行やカンマでデータが区切られているため、プログラムでの読み込みや処理が簡単に行えます。
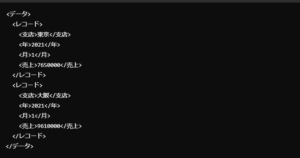
XML(Extensible Markup Language)
XMLは、タグを使ってデータを構造化するフォーマットで、より複雑なデータ構造を表現するのに適しています。XMLの特徴は、データの意味をタグによって明示的に記述できる点です。
例えば、以下のようにデータを表現できます:
JSON(JavaScript Object Notation)
JSONは、JavaScriptで使用される軽量なデータ交換フォーマットです。
シンプルな構造でありながら、ネストされたデータの表現も可能です。
JSON形式の例は次の通りです:

機械可読性の課題
データが機械可読であっても、すべてのデータ形式が常に最適ではありません。
たとえば、PDF(Portable Document Format)やMicrosoft WordのDOCX形式などは、人間が読むために設計されており、機械による処理には適していない場合があります。
これらの形式は、データの表示や印刷を目的としており、構造化されたデータとして扱うのは難しいです。
また、HTML(Hypertext Markup Language)やMicrosoft ExcelのXLSX形式などは、機械可読性と人間の可読性を両立させる中間的な形式ですが、どちらの側面を重視するかによって、トラブルや余計な手間が発生することがあります。
まとめ
機械可読データは、コンピュータによる効率的な処理を可能にするため、現代のデータ管理や分析において重要な役割を果たしています。
CSV、XML、JSONなどのフォーマットは、それぞれ異なる特性を持ち、データの性質や用途に応じて使い分けることが求められます。
一方で、PDFやDOCXなどの形式は機械可読性に欠けるため、データ処理には適していないことが多いです。
機械可読性を理解し、適切なデータ形式を選択することで、効率的なデータ管理と分析が実現できます。
さらに参考してください。