
高可用性(HA:High Availability)は、ITインフラやアプリケーション設計において極めて重要な概念です。
企業の業務システムやクラウドサービスでは、システムの停止がビジネスに与える影響が大きいため、常時稼働(24/365)を目指す構成が求められます。
この記事では、高可用性の定義から実現手法、実際のアーキテクチャ例、そして稼働率を数値で評価する方法までを、ITの専門知識をベースに詳しく解説します。
高可用性(HA)とは何か?
可用性と高可用性の違い
まず基本となるのは「可用性(Availability)」です。
これは、システムがユーザーから見て常に利用可能である状態を意味します。
対して、高可用性(High Availability)とは、システムが停止・中断する時間や頻度を最小限に抑えるための設計思想および構成を指します。
ポイント: 単に「止まりにくい」だけでなく、「止まってもすぐ復旧できる」仕組みが組み込まれていることが重要です。
高可用性を実現する主な手法
冗長化(Redundancy)
冗長化とは、同じ機能を持つコンポーネントを複数配置して、一部が故障してもシステム全体を継続させる設計です。
主な冗長化の例:
-
サーバー冗長化(N+1構成)
-
ネットワーク経路の多重化
-
ストレージのRAID構成
クラスタリング(Clustering)
複数のサーバーを1つのシステムとして動作させるクラスタリング技術により、1台が停止しても他のノードが処理を引き継ぎ、システム全体の可用性を維持します。
クラスタ構成の例:
-
アクティブ-アクティブ型クラスタ:複数ノードが同時に稼働
-
アクティブ-スタンバイ型クラスタ:メインのノードが停止するとスタンバイが即座に切り替え
自動フェイルオーバーとレプリケーション
-
フェイルオーバー:障害発生時に、待機系システムに自動で切り替える機能
-
レプリケーション:データをリアルタイムまたは定期的に複製しておくことで、障害時にも最新の状態でサービス継続が可能
具体例:
-
MySQLのレプリケーション
-
KubernetesのPod自動再スケジューリング
-
AWS Auto ScalingやELBとの連携
稼働率(Availability Rate)という評価指標
高可用性システムの評価において、稼働率という数値が重要な指標となります。
これは、理論上どれだけの時間、システムが利用可能であったかを示すものです。
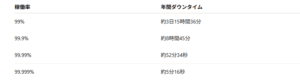
Tip: 「ファイブナイン(99.999%)」は金融や医療など、停止が致命的な業界で求められるレベルです。
高可用性の実装に役立つ技術スタック
クラウドサービスと高可用性
近年ではクラウドインフラの利用が進み、AWS、Azure、Google Cloudなどが高可用性をサポートする機能を提供しています。
実例:
-
AWS Multi-AZ構成
-
GCPのCloud Load Balancer + Managed Instance Groups
-
Azure Availability Sets と Availability Zones
仮想化とコンテナ技術
-
仮想マシンのライブマイグレーション
-
Kubernetesの自己修復機能
-
Docker Swarmでのサービスレベル冗長化
これらを適切に組み合わせることで、オンプレミスでもクラウドでも高可用性の実現が可能です。
まとめ
この記事では、高可用性(HA:High Availability)について、以下のポイントを中心に解説しました。
-
高可用性とは、停止時間を極限まで減らすための構成と考え方
-
冗長化・クラスタリング・自動フェイルオーバーなどが中心技術
-
稼働率を評価軸とし、目標とする可用性レベルを設定する
-
クラウドや仮想化技術の活用により、柔軟かつコスト効率よくHAを実現可能
高可用性の設計は、システムの信頼性・継続性・ビジネス価値に直結する重要な技術分野です。
インフラエンジニア、システムアーキテクトにとって不可欠な知識として、今後も注目され続けるでしょう。