

AIや深層学習の分野では、「データの特徴を自動で学習する技術」が非常に重要視されています。
その中でも代表的な手法の一つが オートエンコーダ(Autoencoder) です。
オートエンコーダは、画像や音声などの大量データから、本質的な特徴を抽出するためのニューラルネットワークであり、特徴量学習・次元削減・異常検知など幅広い用途で活用されています。
また、近年注目される生成AI技術の基礎としても重要な存在です。
この記事では、オートエンコーダの基本構造や仕組み、主な用途、種類、VAE(変分オートエンコーダ)との関係まで、初心者にも分かりやすく解説します。
オートエンコーダ(Autoencoder)とは
オートエンコーダとは、入力データを一度圧縮し、その後元の形へ復元するニューラルネットワークです。
日本語では「自己符号化器」と呼ばれます。
特徴的なのは、
- 入力データ
- 出力データ
が同じになるように学習する点です。
例えば画像データなら、
入力画像 → 圧縮 → 復元画像という流れで処理されます。
ネットワークは「できるだけ元画像を再現する」ように学習します。
オートエンコーダの基本構造
オートエンコーダは主に以下の2つで構成されます。
- エンコーダ(Encoder)
- デコーダ(Decoder)
エンコーダ(Encoder)
エンコーダは、入力データを低次元の特徴表現へ圧縮する部分です。
例えば、
- 画像
- 音声
- センサーデータ
などの高次元データを、より小さな情報へ変換します。
この圧縮された情報を「潜在表現(Latent Representation)」と呼びます。
デコーダ(Decoder)
デコーダは、圧縮された潜在表現から元データを復元する部分です。
つまり、
圧縮データ → 元画像の再構成を行います。
ネットワーク全体は、入力と出力ができるだけ一致するように学習されます。
オートエンコーダの仕組み
オートエンコーダでは、入力データをそのままコピーするのではなく、「重要な特徴だけを残して圧縮」しようとします。
例えば顔画像の場合、
- 目の位置
- 輪郭
- 鼻や口の特徴
など、本質的な情報を抽出します。
不要な細部を削減することで、データの特徴を効率的に学習できます。
潜在表現(Latent Representation)とは
潜在表現とは、データの特徴を凝縮した内部表現のことです。
オートエンコーダの中心的な概念といえます。
例えば、
- 猫画像
- 犬画像
を学習した場合、潜在空間では「耳の形」「顔の輪郭」などの特徴が整理される可能性があります。
この潜在表現を利用することで、
- データ分類
- クラスタリング
- 異常検知
などを効率的に行えます。
オートエンコーダは教師なし学習
オートエンコーダは「教師なし学習」に分類されます。
教師なし学習とは
教師なし学習とは、正解ラベルを使わずにデータの特徴を学ぶ手法です。
通常の画像分類では、
猫 → 正解
犬 → 正解のようなラベルが必要です。
一方オートエンコーダでは、
入力 = 正解となるため、ラベル付けが不要です。
そのため、大量データから効率的に特徴を学習できます。
主成分分析(PCA)との違い
オートエンコーダは、しばしば「PCA(主成分分析)の非線形版」と説明されます。
PCAとは
PCAは、データを少ない次元へ圧縮する代表的な統計手法です。
ただしPCAは「線形変換」しか扱えません。
オートエンコーダの強み
オートエンコーダはニューラルネットワークを利用するため、非線形な特徴も学習できます。
つまり、
- 複雑な画像特徴
- 音声パターン
- 高度なデータ構造
も表現可能です。
そのため、現代の深層学習ではPCAより高性能なケースも多くあります。
オートエンコーダの代表的な用途
画像の特徴抽出
画像認識では、高次元画像から重要特徴を抽出するために利用されます。
CNN(畳み込みニューラルネットワーク)と組み合わせるケースもあります。
異常検知
非常に有名な用途が異常検知です。
正常データだけを学習させると、オートエンコーダは正常パターンの復元が得意になります。
しかし異常データを入力すると、うまく復元できません。
その結果、「再構成誤差」が大きくなります。
再構成誤差とは
入力と復元結果のズレを表す値です。
例えば、
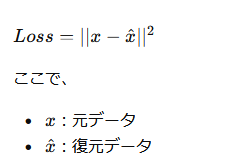
を表しています。
誤差が大きいほど、「普段と異なるデータ」である可能性が高いと判断できます。
ノイズ除去
画像や音声からノイズを除去する用途にも使われます。
デノイジングオートエンコーダとは
デノイジングオートエンコーダ(Denoising Autoencoder)は、入力へノイズを加えて学習する手法です。
例えば、
- ノイズ付き画像
- 欠損データ
を入力し、元の綺麗なデータを復元するよう学習します。
これにより、より頑健な特徴表現を獲得できます。
変分オートエンコーダ(VAE)とは
近年特に重要なのが、変分オートエンコーダ(Variational Autoencoder:VAE) です。
VAEでは、潜在空間を「確率分布」として扱います。
これにより、
- 新しい画像生成
- データ生成
- 生成AI
などが可能になります。
Stable Diffusionなどの画像生成AIにも、VAEの考え方が活用されています。
オートエンコーダのメリット
ラベル不要で学習できる
大量の未ラベルデータを活用できます。
高次元データに強い
画像や音声など複雑なデータ処理に向いています。
特徴抽出能力が高い
重要な特徴を自動学習できます。
オートエンコーダのデメリット
単純コピーになる場合がある
圧縮が不十分だと、特徴学習ではなく単なるコピー学習になることがあります。
学習設計が難しい
潜在次元数やネットワーク設計によって性能が大きく変化します。
Transformer時代でも重要な理由
現在はTransformer系モデルが主流ですが、オートエンコーダの考え方は依然として重要です。
特に、
- 自己教師あり学習
- 特徴量圧縮
- 潜在空間学習
- 生成モデル
など、多くのAI技術に影響を与えています。
生成AIを理解するうえでも、オートエンコーダは基礎知識として非常に重要です。
まとめ
オートエンコーダ(Autoencoder)は、入力データを圧縮し、再構成することで特徴を学習するニューラルネットワークです。
教師なし学習によって大量データから本質的な特徴を抽出できるため、現在でも幅広い分野で利用されています。
ポイントを整理すると、以下の通りです。
- 入力データを圧縮・復元するモデル
- エンコーダとデコーダで構成される
- 潜在表現を学習できる
- 教師なし学習に分類される
- 異常検知や特徴抽出に強い
- VAEは生成AI技術の基礎になっている
AI・深層学習を体系的に学びたい方にとって、オートエンコーダは理解しておきたい重要技術の一つです。
こちらもご覧ください:双方向RNN(BiRNN)とは?通常のRNNとの違いや仕組みをわかりやすく解説


