

近年、生成AIや機械学習の分野で「ファインチューニング(Fine Tuning)」という言葉を耳にする機会が増えています。
ChatGPTのような大規模AIモデルを、自社業務や特定分野向けに最適化する際に重要となる技術です。
しかし、
- 「事前学習との違いが分からない」
- 「転移学習とは何が違うの?」
- 「なぜファインチューニングが必要なのか?」
と疑問を持つ方も多いのではないでしょうか。
この記事では、ファインチューニングの仕組みや目的、転移学習との違い、活用事例について、初心者にも分かりやすく解説します。
ファインチューニングとは
ファインチューニング(Fine Tuning)とは、すでに学習済みのAIモデルに対して、新しいデータを追加学習させ、特定用途向けに最適化する手法です。
特に近年では、生成AIや大規模言語モデル(LLM)の分野で重要な技術となっています。
そもそもAIモデルはどのように学習するのか
AIモデル、特にニューラルネットワークは、大量のデータを学習することで知識を獲得します。
ニューラルネットワークの基本
ニューラルネットワークでは、人工ニューロン同士が接続されており、その接続の強さを「重み(Weight)」と呼びます。
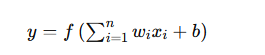
学習によって、この重みが調整され、AIは特徴やパターンを理解していきます。
なぜ事前学習モデルが使われるのか
現在のAI開発では、ゼロから巨大モデルを作るケースは少なく、多くの場合は「事前学習済みモデル(Pre-trained Model)」が利用されます。
大規模学習には膨大なコストが必要
例えば大規模言語モデルを一から開発するには、以下のような資源が必要です。
- 大量のテキストデータ
- 高性能GPU
- 莫大な計算コスト
- 長時間の学習環境
そのため、多くの企業や開発者は、すでに学習済みのモデルをベースとして利用します。
事前学習モデルの課題
事前学習済みモデルは汎用性が高い反面、特定分野には弱いことがあります。
例えば、
- 医療専門用語
- 法律文書
- 社内マニュアル
- 金融データ
- 業界独自の表現
などに対しては、十分な精度を出せない場合があります。
これは、汎用モデルが「広く浅い知識」を持つように学習されているためです。
ファインチューニングの仕組み
そこで活用されるのが、ファインチューニングです。
既存モデルに対して、新しい専門データを追加学習させることで、特定分野に強いAIへと調整します。
基本的な流れ
ファインチューニングは、一般的に以下の流れで行われます。
- 事前学習済みモデルを用意
- 専門データを追加
- 一部の層を再学習
- 特定用途向けに最適化
例えば、
- 医療AIなら医療論文
- 法務AIなら契約書
- 社内AIなら社内ナレッジ
を追加学習させることで、専門性を高められます。
なぜ一部の層だけを調整するのか
ファインチューニングでは、すべての層を完全に学習し直すわけではありません。
入力側は固定されることが多い
AIモデルの初期層では、基本的な特徴を学習しています。
例えば画像認識なら、
- 線
- 色
- エッジ
などです。
そのため、初期層は固定し、後半部分のみ調整するケースが一般的です。
出力側を重点的に調整
最終的な判断に近い層を調整することで、既存知識を維持しながら専門性を追加できます。
転移学習との違い
ファインチューニングとよく比較されるのが「転移学習(Transfer Learning)」です。
転移学習とは
転移学習は、既存モデルの知識を別のタスクへ活用する手法です。
特に狭義では、
- 既存モデルを固定
- 新たに追加した層のみ学習
する方法を指すことがあります。
ファインチューニングとの違い
| 項目 | ファインチューニング | 転移学習 |
|---|---|---|
| 学習範囲 | 一部または全体を再調整 | 追加層中心 |
| 元モデル | 一部更新する | 基本固定 |
| 柔軟性 | 高い | 比較的低い |
| 計算コスト | やや高い | 比較的低い |
現代AIにおけるファインチューニングの重要性
現在では、多くの生成AIサービスでファインチューニング技術が利用されています。
活用例
カスタマーサポートAI
企業独自のFAQやマニュアルを学習させることで、回答精度を向上できます。
医療AI
医療データを追加学習し、診断支援に活用します。
法務AI
契約書や法律文書に特化した回答が可能になります。
画像認識AI
特定製品の不良検知など、工場向けAIにも活用されています。
ファインチューニングのメリット
少ないデータでも高性能化できる
ゼロから学習する必要がないため、比較的少量の専門データでも効果が期待できます。
学習コストを削減できる
既存モデルを活用するため、開発コストを抑えられます。
専門性を強化できる
特定業界向けの高精度AIを構築できます。
ファインチューニングの課題
一方で、注意点もあります。
過学習(Overfitting)
特定データに偏りすぎると、汎用性が失われる可能性があります。
計算コストが必要
大規模モデルではGPUなど高性能環境が必要になります。
元モデルの性能低下
調整の仕方によっては、本来の能力が損なわれる場合もあります。
LoRAなど軽量ファインチューニングも登場
近年では、「LoRA(Low-Rank Adaptation)」のような軽量ファインチューニング技術も注目されています。
これは、モデル全体を更新せず、一部パラメータのみを効率よく調整する方法です。
その結果、
- GPU負荷の削減
- 学習時間短縮
- コスト削減
などが可能になっています。
まとめ
ファインチューニングとは、事前学習済みAIモデルを特定用途向けに再調整する技術です。
既存モデルの知識を活かしながら、
- 医療
- 法律
- 金融
- 社内業務
など、専門分野に強いAIを効率的に構築できます。
現在の生成AI時代では、単に大規模モデルを使うだけでなく、「どのように自社向けに最適化するか」が重要になっています。
ファインチューニングは、その中心となる非常に重要な技術といえるでしょう。
こちらもご覧ください:LeNetとは?CNN時代を切り開いた画像認識AIの仕組みをわかりやすく解説


