

近年のAI・機械学習では、「データ同士の似ている・似ていない」を学習する技術が重要視されています。
たとえば、
- 顔認証
- 類似画像検索
- レコメンドシステム
- 音声照合
- 自己教師あり学習
など、多くの分野で「データ間の距離」を扱う仕組みが活用されています。
その中心的な技術の一つが「Contrastive Loss(コントラスト損失)」です。
Contrastive Lossは、「似ているデータは近づけ、異なるデータは遠ざける」という考え方にもとづく損失関数であり、特徴表現(埋め込み)の学習で広く利用されています。
本記事では、Contrastive Lossの仕組みや特徴、活用例、近年注目される理由について、初心者にもわかりやすく解説します。
Contrastive Lossとは?
Contrastive Lossとは、2つのデータの類似性を学習するための損失関数です。
通常の分類モデルでは、
- 「これは猫」
- 「これは犬」
のようにカテゴリを直接予測します。
一方、Contrastive Lossでは、
- 「この2つは似ているか」
- 「この2つは異なるか」
という“ペア関係”を学習します。
どのように学習するのか?
Contrastive Lossでは、入力として「2つのサンプル」を与えます。
そして、それらが
- 同じクラスか
- 異なるクラスか
を示すラベルを利用して学習を行います。
正例ペア(Positive Pair)
同じクラスに属するデータ同士を「正例ペア」と呼びます。
たとえば、
- 同じ人物の顔画像
- 同じ商品の異なる写真
- 同じ意味を持つ文章
などです。
正例ペアでは、「特徴空間上の距離」を小さくするように学習します。
負例ペア(Negative Pair)
異なるクラスに属するデータ同士を「負例ペア」と呼びます。
たとえば、
- 別人の顔画像
- 異なる商品の画像
- 内容が異なる文章
などです。
負例ペアでは、特徴空間上で十分離れるように学習します。
埋め込み空間とは?
Contrastive Lossを理解するうえで重要なのが「埋め込み空間(Embedding Space)」です。
これは、データを数値ベクトルへ変換した空間のことです。
AIモデルは、
- 類似データは近く
- 非類似データは遠く
配置されるように特徴表現を学習します。
イメージ例
たとえば顔認証AIでは、
- 同じ人物の顔画像 → 近い位置
- 異なる人物の顔画像 → 遠い位置
になるように学習されます。
その結果、新しい画像が入力された際にも、「距離の近さ」で人物判定が可能になります。
Contrastive Lossの基本的な考え方
Contrastive Lossは、「距離」を使って誤差を計算します。
一般的には、以下のような考え方で動作します。
正例の場合
同じクラスなら距離を小さくする。
つまり、
- 似ているデータ
- 関連性が高いデータ
を近づけます。
負例の場合
異なるクラスなら一定以上離す。
ただし、無限に遠ざけるわけではありません。
ここで重要になるのが「マージン(Margin)」です。
マージン(Margin)とは?
マージンとは、「異なるデータ同士が最低限離れているべき距離」のことです。
![]()
なぜマージンが必要なのか?
もし負例を際限なく遠ざけようとすると、
- 学習が不安定になる
- 不要な計算が増える
- 埋め込み空間が崩れる
といった問題が発生します。
そのため、「十分離れていれば、それ以上は損失を与えない」という設計になっています。
距離尺度には何が使われる?
Contrastive Lossでは、データ間距離の計算が重要になります。
もっとも一般的なのは「ユークリッド距離」です。
ユークリッド距離とは?
2点間の直線距離を表す指標です。
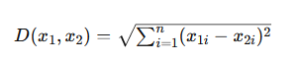
AIでは、この距離を使って「どれだけ似ているか」を判断します。
その他の距離尺度
用途によっては以下も利用されます。
- コサイン類似度
- マンハッタン距離
- ハミング距離
特に自然言語処理では、ベクトルの向きを比較するコサイン類似度がよく利用されます。
Contrastive Lossの活用例
顔認証
もっとも有名な利用例の一つです。
顔認証では、
- 同一人物 → 距離を近づける
- 別人 → 距離を離す
ように学習することで、高精度な認証を実現しています。
スマートフォンの顔ロック解除などにも応用されています。
類似画像検索
ECサイトや画像検索サービスでは、似た画像を探す技術に利用されています。
たとえば、
- 同じデザインの服
- 類似家具
- 似た風景写真
などを距離ベースで検索できます。
自己教師あり学習(Self-Supervised Learning)
近年、Contrastive Lossは自己教師あり学習でも注目されています。
自己教師あり学習とは、大量のラベルなしデータから特徴を学習する技術です。
代表的な手法には、
- SimCLR
- MoCo
- CLIP
などがあります。
特に生成AI時代では、「大量データから効率よく特徴を学ぶ技術」として重要性が高まっています。
Contrastive Lossのメリット
ラベル不足に強い
通常の教師あり学習では大量のラベル付きデータが必要です。
しかしContrastive Lossでは、
- 類似ペア
- 非類似ペア
の情報だけでも学習しやすいため、ラベル不足環境に強い特徴があります。
汎用的な特徴表現を学べる
単純な分類ではなく、「データ構造そのもの」を学習できるため、転移学習や検索システムとの相性も良好です。
Contrastive Lossの課題
ペア作成が難しい
学習品質は、
- どの正例を選ぶか
- どの負例を選ぶか
に大きく依存します。
特に「Hard Negative」と呼ばれる、似ているが異なるデータの扱いは重要な研究テーマです。
大規模計算が必要
大量のペア比較を行うため、計算コストが高くなりやすい特徴があります。
そのため近年では、
- 効率的なサンプリング
- メモリバンク
- バッチ最適化
などの工夫も進んでいます。
まとめ
Contrastive Lossとは、「似たデータは近づけ、異なるデータは遠ざける」ことで特徴表現を学習する損失関数です。
主に、
- 顔認証
- 類似画像検索
- レコメンド
- 自己教師あり学習
などで活用されています。
また、埋め込み空間を適切に構築できるため、近年の生成AIや大規模表現学習でも重要な技術となっています。
AI開発では単なる分類だけでなく、「データ同士の関係性」を学ぶ重要性が高まっており、Contrastive Lossはその中核を担う存在となっています。


