

機械学習では、モデルを複雑にすればするほど学習データへの適合度を高めることができます。
しかし、その一方で、
- ノイズ
- 外れ値
- 偶然の偏り
まで学習してしまい、未知データに対する性能が低下する「過学習(Overfitting)」という問題が発生します。
この過学習を防ぐために使われる技術が「正則化(Regularization)」です。
その中でも、「本当に必要な特徴量だけを使う」という考え方を極端に追求した手法が「L0正則化(L0 Regularization)」です。
L0正則化は、不要なパラメータを徹底的に削減し、シンプルで解釈しやすいモデルを作ることを目的としています。
本記事では、L0正則化の仕組みやL1・L2正則化との違い、スパースモデルとの関係、実用上の課題までをわかりやすく解説します。
L0正則化とは?
L0正則化とは、「ゼロではないパラメータの数」にペナルティを与える正則化手法です。
簡単に言えば、「使う特徴量をできるだけ少なくする」ための技術です。
なぜ正則化が必要なのか?
機械学習モデルは、複雑にするほど訓練データへ強く適合できます。
しかし複雑すぎるモデルは、
- ノイズ
- 外れ値
- 偶然の偏り
まで学習してしまいます。
これが「過学習」です。
過学習のイメージ
たとえば試験勉強で、
- 本質を理解している → 応用問題にも対応できる
- 過去問を丸暗記した → 少し変わると解けない
という違いがあります。
過学習したAIは、後者の状態に近くなります。
L0正則化の基本的な考え方
L0正則化では、「非ゼロのパラメータ数」そのものにペナルティを与えます。
L0正則化の数式イメージ
基本形は以下のようになります。

を表します。
「L0ノルム」とは?
![]()
これは、「ゼロでない要素の個数」を数えているだけです。
具体例
たとえば、
![]()
の場合、
- 非ゼロ要素は3個
なので、
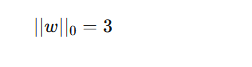
となります。
つまりL0正則化は、「使うパラメータ数を最小化する」方向へ学習を進めます。
L0正則化の特徴
不要な特徴量を完全に削除できる
L0正則化では、一部の重みが完全に0になります。
その結果、
- 不要な特徴量
- 意味の薄い変数
をモデルから除外できます。
スパースモデルを作れる
L0正則化では、「スパース(疎)」なモデルが構築されます。
スパースとは、「多くの値が0である状態」を意味します。
モデルが軽量になる
不要な特徴量を使わないため、
- 計算量削減
- メモリ削減
- 推論高速化
にもつながります。
特にエッジAIや組み込みAIで重要です。
L0正則化の最大のメリット
解釈性が非常に高い
L0正則化は、「どの特徴量を使ったか」が明確になります。
そのため、
- 医療AI
- 金融AI
- リスク分析
など、「なぜその予測をしたのか」が重要な分野と相性が良い特徴があります。
L1正則化との違い
L0正則化は、L1正則化とよく比較されます。
L1正則化
L1正則化では、重みの絶対値和にペナルティを与えます。
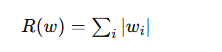
L0正則化との違い
L0正則化
- 「パラメータ数」そのものを削減
- より強力な特徴量選択
- 厳密なスパース化
L1正則化
- 小さい重みを減少
- 計算しやすい
- 実用性が高い
なぜL1正則化がよく使われるのか?
L0正則化には大きな課題があります。
それが「最適化の難しさ」です。
L0正則化の課題
微分できない
L0正則化は、「ゼロかゼロでないか」を扱うため、連続的に微分できません。
そのため、
- 勾配降下法
- 誤差逆伝播法
など、深層学習で標準的な最適化手法を直接適用しにくい特徴があります。
組み合わせ最適化問題になる
どの特徴量を残すべきかは、全組み合わせ探索に近い問題になります。
特徴量数が増えるほど計算量が爆発的に増加します。
NP困難に近い問題
大規模データでは、
- 計算コスト
- メモリ消費
- 探索時間
が非常に大きくなります。
そのため、実務では近似手法が必要になります。
実際には近似法が使われる
実務では、
- L1正則化
- Relaxation手法
- 確率的ゲート
- Sparse Learning
などが利用されることが多くあります。
特にL1正則化は、
- 微分可能
- 実装しやすい
- 高速学習可能
という理由から広く使われています。
L0正則化の活用分野
特徴量選択
大量の特徴量から、本当に重要な変数だけを選択したい場合に有効です。
医療AI
医療分野では、「どの特徴が診断に重要だったか」を明確にする必要があります。
L0正則化は高い解釈性を提供できます。
エッジAI・IoT
軽量モデルを作りやすいため、
- モバイル端末
- IoT機器
- 組み込みAI
との相性も良好です。
深層学習との関係
近年では、大規模ニューラルネットワークでも、
- モデル圧縮
- スパース化
- 軽量化
の目的でL0的アプローチが研究されています。
特に、
- Sparse Transformer
- Mixture of Experts(MoE)
- 動的ネットワーク
などでは、「必要な部分だけ使う」という考え方が重要になっています。
まとめ
L0正則化とは、「ゼロでないパラメータ数」にペナルティを与える正則化手法です。
特徴として、
- 強力な特徴量選択
- スパースモデル構築
- 高い解釈性
- 軽量モデル化
などがあります。
一方で、
- 微分できない
- 最適化が難しい
- 計算コストが高い
という課題もあります。
そのため実務では、L1正則化など近似的な手法がよく利用されています。
しかし近年では、AIモデルの軽量化・効率化が重要視される中で、L0正則化の考え方は再び注目を集めています。
こちらもご覧ください:正則化(Regularization)とは?過学習を防ぐ機械学習の重要技術をわかりやすく解説


