

機械学習では、モデルを複雑にするほど学習データへの適合度を高めることができます。
しかし、モデルが複雑になりすぎると、
- ノイズ
- 外れ値
- 偶然の偏り
まで学習してしまい、未知データへの予測性能が低下する「過学習(Overfitting)」という問題が発生します。
この過学習を防ぐために利用されるのが「正則化(Regularization)」です。
その中でも、不要な特徴量を自動的に削除できることで特に有名なのが「L1正則化(L1 Regularization)」です。
L1正則化は、モデルをシンプルに保ちながら、重要な特徴量だけを選び出せるため、機械学習や統計解析で広く利用されています。
本記事では、L1正則化の仕組みや特徴、L2正則化との違い、ラッソ回帰との関係までをわかりやすく解説します。
L1正則化とは?
L1正則化とは、モデルのパラメータの「絶対値の和」にペナルティを与える正則化手法です。
簡単に言えば、「不要なパラメータを減らして、モデルをシンプルにする」ための技術です。
なぜ正則化が必要なのか?
機械学習モデルは、複雑にするほど訓練データへ強く適合できます。
しかし適合しすぎると、
- ノイズ
- 偶然のパターン
- 外れ値
まで覚えてしまいます。
これが「過学習」です。
過学習のイメージ
たとえば試験勉強で、
- 本質を理解している → 応用問題にも対応できる
- 問題文を丸暗記している → 少し変わると解けない
という違いがあります。
過学習したAIは、後者の状態に近くなります。
L1正則化の仕組み
L1正則化では、通常の損失関数に「正則化項」を追加します。
L1正則化の数式
基本的な形は以下です。

を表します。
正則化係数 λ\lambda の役割
λ\lambda は、正則化の強さを調整するハイパーパラメータです。
λ\lambda が小さい場合
- 通常の学習を重視
- 複雑なモデルになりやすい
λ\lambda が大きい場合
- 強くペナルティを与える
- パラメータが小さくなる
- モデルがシンプルになる
L1正則化の最大の特徴
パラメータを「ゼロ」にできる
L1正則化の最も重要な特徴は、「不要なパラメータを完全に0へ近づける」性質を持つことです。
なぜ重要なのか?
パラメータが0になるということは、「その特徴量を使わない」ことを意味します。
つまりL1正則化には、
- 自動特徴量選択
の効果があります。
特徴量選択とは?
機械学習では、多数の特徴量が存在することがあります。
たとえば住宅価格予測なら、
- 面積
- 築年数
- 駅距離
- 周辺施設
- 日照条件
など、非常に多くの変数があります。
しかし、すべてが重要とは限りません。
L1正則化は、重要度の低い特徴量を自動的に除外できます。
スパースモデルとは?
L1正則化によって、多くの重みが0になります。
このように、「ほとんどの値が0である状態」を「スパース(Sparse)」と呼びます。
スパースモデルのメリット
- 計算量削減
- メモリ削減
- 解釈性向上
- 推論高速化
などがあります。
特にエッジAIやIoT分野で重要です。
ラッソ回帰(Lasso Regression)とは?
回帰分析でL1正則化を適用したものを、「ラッソ回帰(Lasso Regression)」と呼びます。
正式名称は、「Least Absolute Shrinkage and Selection Operator」です。
ラッソ回帰の特徴
ラッソ回帰では、
- 不要な特徴量を削除
- モデルを単純化
- 解釈しやすい予測
が可能になります。
L2正則化との違い
L1正則化は、L2正則化とよく比較されます。
L2正則化の数式
L2正則化は、パラメータの二乗和を利用します。
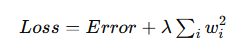
L1とL2の違い
L1正則化
- 一部の重みを0にする
- 特徴量選択が可能
- スパース化に強い
L2正則化
- 重み全体を滑らかに小さくする
- 安定性が高い
- 深層学習で広く利用
どちらを選ぶべき?
用途によって適切な手法は異なります。
L1正則化が向くケース
- 特徴量が非常に多い
- 不要変数を除外したい
- 解釈性が重要
L2正則化が向くケース
- 安定性を重視
- 深層学習
- 大規模モデル
実務では、両者を組み合わせた「Elastic Net」もよく利用されます。
L1正則化のメリット
モデルがシンプルになる
不要な特徴量を削減できるため、モデルが軽量になります。
解釈性が高い
どの特徴量が重要かを理解しやすくなります。
これは、
- 医療AI
- 金融AI
- リスク分析
などで非常に重要です。
高次元データに強い
特徴量数が非常に多い問題でも有効です。
特に、
- 遺伝子解析
- テキスト解析
- 自然言語処理
などで活用されます。
L1正則化の注意点
情報を削りすぎる場合がある
強く正則化しすぎると、本来必要な特徴量まで削除してしまう可能性があります。
相関の強い特徴量に弱い
似た特徴量が複数ある場合、どれか1つだけ残す傾向があります。
そのため、安定性が低くなるケースもあります。
深層学習でのL1正則化
近年では、
- モデル圧縮
- スパースニューラルネットワーク
- 軽量AI
の研究でもL1正則化が利用されています。
特にエッジAIでは重要です。
まとめ
L1正則化(L1 Regularization)とは、パラメータの絶対値和へペナルティを与える正則化手法です。
最大の特徴は、不要な特徴量を自動的に削除できる点にあります。
また、
- スパースモデル構築
- 特徴量選択
- モデル軽量化
- 解釈性向上
など、多くのメリットがあります。
回帰分析では「ラッソ回帰」として知られ、現代の機械学習・統計解析において重要な基盤技術の一つとなっています。
こちらもご覧ください:L0正則化とは?特徴量を最小限に絞る機械学習の正則化手法をわかりやすく解説


