

ディープラーニング(深層学習)の性能を大きく左右する要素のひとつが「活性化関数」です。
なかでも広く利用されているのがReLU(Rectified Linear Unit)ですが、そのReLUには「死んだReLU問題(Dying ReLU)」という課題があります。
この問題を改善するために考案されたのが Leaky ReLU(Leaky Rectified Linear Unit) です。
現在では、画像認識や自然言語処理など、さまざまなAIモデルで利用されており、深層学習を理解するうえで重要な活性化関数のひとつとなっています。
この記事では、Leaky ReLU関数の仕組みや特徴、ReLUとの違い、メリット・デメリットについて初心者向けにわかりやすく解説します。
Leaky ReLU関数とは?
Leaky ReLU関数は、ニューラルネットワークで利用される「活性化関数」の一種です。
活性化関数とは、ニューラルネットワークの各ニューロンが受け取った値を変換し、次の層へ伝えるための仕組みです。
この非線形変換によって、AIは複雑なパターンや特徴を学習できるようになります。
Leaky ReLUは、従来のReLU関数を改良したもので、負の値に対してもわずかに出力を持つよう設計されています。
Leaky ReLUが登場した背景
従来の活性化関数の課題
初期のニューラルネットワークでは、以下のような活性化関数が主流でした。
- シグモイド関数(Sigmoid)
- tanh関数
しかし、これらには「勾配消失問題(Vanishing Gradient Problem)」という大きな問題がありました。
勾配消失とは、学習時に誤差を逆方向へ伝播させる際、微分値が繰り返し掛け合わされることで極端に小さくなり、入力層付近で学習が進まなくなる現象です。
深いニューラルネットワークでは特に深刻な問題となっていました。
ReLU関数による改善
この問題を軽減するために登場したのがReLU関数です。
ReLUは次のようなシンプルな関数です。
![]()
特徴は以下の通りです。
- 入力が正ならそのまま出力
- 入力が負なら0を出力
ReLUは正の領域で勾配が一定になるため、勾配消失が起こりにくく、ディープラーニングの発展に大きく貢献しました。
さらに、
- 計算が高速
- 実装が簡単
- GPU処理と相性が良い
といった利点もあります。
ReLUの欠点「死んだReLU問題」とは?
便利なReLUですが、問題点もあります。
それが「死んだReLU問題(Dying ReLU)」です。
ReLUでは、入力が負になると出力が常に0になります。
この状態が続くと、そのニューロンの重み更新が止まり、学習できなくなる場合があります。
つまり、
- ニューロンが反応しなくなる
- 誤差が前の層へ伝わらない
- 学習効率が低下する
という問題が発生します。
特に学習率が高すぎる場合や、初期値の設定が適切でない場合に起こりやすいとされています。
Leaky ReLU関数の仕組み
Leaky ReLUは、この「死んだReLU問題」を改善するために考案されました。
Leaky ReLUでは、負の領域でも完全に0にせず、わずかな傾きを持たせます。
数式は以下のようになります。
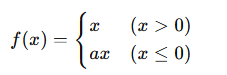
ここでの「a」は小さな定数で、一般的には0.01程度が使われます。
Leaky ReLUの特徴
負の領域でも勾配が残る
Leaky ReLU最大の特徴は、負の入力でも勾配が0にならないことです。
そのため、
- ニューロンが停止しにくい
- 学習が安定しやすい
- 深いネットワークでも性能を維持しやすい
というメリットがあります。
ReLUとLeaky ReLUの違い
| 項目 | ReLU | Leaky ReLU |
|---|---|---|
| 正の領域 | そのまま出力 | そのまま出力 |
| 負の領域 | 常に0 | 小さな値を出力 |
| 勾配 | 負側で0 | 負側でもわずかに存在 |
| 死んだReLU問題 | 起こりやすい | 起こりにくい |
| 計算コスト | 非常に低い | 低い |
Leaky ReLUは、ReLUのシンプルさを保ちながら、弱点を改善した活性化関数といえます。
Leaky ReLUのメリット
学習停止を防ぎやすい
負の値でも勾配が存在するため、ニューロンが完全に学習停止するリスクを減らせます。
深層学習との相性が良い
層が深いネットワークでも、勾配が流れやすくなります。
実装が簡単
ReLUとほぼ同じ構造のため、導入しやすいのも利点です。
Leaky ReLUのデメリット
最適な係数「a」の調整が必要
負の領域で使う係数「a」は手動で設定する必要があります。
設定によっては、
- 学習が不安定になる
- 性能が十分に出ない
こともあります。
必ずしもReLUより優れるとは限らない
タスクによっては、通常のReLUの方が高性能な場合もあります。
そのため、実際の開発現場では、
- ReLU
- Leaky ReLU
- PReLU
- ELU
- GELU
などを比較しながら選択するケースが一般的です。
Leaky ReLUはどんな場面で使われる?
Leaky ReLUは、以下のような分野で利用されています。
画像認識
- 物体検出
- 顔認識
- 医療画像解析
自然言語処理
- テキスト分類
- 感情分析
- チャットボット
音声処理
- 音声認識
- 音声生成AI
特に、深いニューラルネットワークや学習が不安定になりやすいモデルで効果を発揮します。
まとめ
Leaky ReLU関数は、ReLU関数の弱点である「死んだReLU問題」を改善するために開発された活性化関数です。
特徴を整理すると、以下の通りです。
- 負の領域でもわずかに勾配を持つ
- ニューロンの学習停止を防ぎやすい
- 深層学習で安定した学習を実現しやすい
- ReLUと同様に計算コストが低い
現在のAI開発では、用途に応じて複数の活性化関数を使い分けることが重要になっています。
Leaky ReLUは、ディープラーニングの理解を深めるうえで非常に重要な技術のひとつです。
ReLUとの違いを理解することで、ニューラルネットワーク設計への理解もさらに深まるでしょう。


