

近年のAI技術、とくにディープラーニング(深層学習)の発展を支えている重要な技術のひとつに「活性化関数」があります。
その中でも、現在もっとも広く利用されている活性化関数が ReLU関数(Rectified Linear Unit) です。
ReLUは、画像認識や音声認識、自動運転など、さまざまなAIモデルで採用されており、現代のニューラルネットワークに欠かせない存在となっています。
この記事では、ReLU関数の基本的な仕組みからメリット・デメリット、派生手法までを初心者にもわかりやすく解説します。
ReLU関数とは?
ReLU(Rectified Linear Unit)は、ニューラルネットワークで使用される「活性化関数」の一種です。
活性化関数とは、ニューラルネットワークの各ノード(ニューロン)が受け取った値を変換し、次の層へ渡すための仕組みです。
この変換によって、AIは単純な線形計算だけでは表現できない複雑なパターンを学習できるようになります。
ReLU関数は、以下の数式で表されます。
![]()
非常にシンプルな関数で、
- 入力値が「0より大きい」ときはそのまま出力
- 入力値が「0以下」のときは「0」を出力
という特徴があります。
ReLU関数のグラフイメージ
ReLU関数のグラフは非常に単純です。
![]()
正の値の場合
入力が正であれば、そのまま直線的に増加します。
たとえば:
- 入力が「1」→ 出力は「1」
- 入力が「5」→ 出力は「5」
となります。
負の値の場合
入力が負であれば、常に「0」になります。
たとえば:
- 入力が「-1」→ 出力は「0」
- 入力が「-10」→ 出力は「0」
です。
このシンプルさが、ReLU関数の大きな強みになっています。
なぜReLU関数が重要なのか?
勾配消失問題を起こしにくい
従来のニューラルネットワークでは、シグモイド関数やtanh関数がよく使われていました。
しかし、これらには「勾配消失問題(Vanishing Gradient Problem)」という大きな課題がありました。
勾配消失問題とは、学習時に誤差を逆方向へ伝播する過程で、微分値がどんどん小さくなり、入力層に近い部分で学習が進まなくなる現象です。
ReLU関数は、正の領域では微分値が一定になるため、勾配が極端に小さくなりにくいという特徴があります。
その結果、
- 深いニューラルネットワークでも学習しやすい
- 学習速度が向上する
- 大規模データでも効率よく訓練できる
といったメリットがあります。
ReLU関数がディープラーニングで広く使われる理由
計算コストが低い
ReLU関数は「0より大きいかどうか」を判定するだけの単純な処理です。
そのため、
- 計算量が少ない
- GPUとの相性が良い
- 学習時間を短縮できる
という利点があります。
特に、画像認識で利用されるCNN(畳み込みニューラルネットワーク)では、膨大な計算が必要になるため、ReLUの軽量さが大きく役立っています。
ReLU関数のデメリット
便利なReLU関数ですが、欠点も存在します。
Dead ReLU(死んだReLU問題)
ReLUでは、入力が負の値になると出力が常に0になります。
この状態が長く続くと、特定のニューロンが学習できなくなることがあります。
これが「Dead ReLU(死んだReLU問題)」です。
一度この状態になると、
- 重み更新が止まる
- ニューロンが機能しなくなる
- モデル性能が低下する
可能性があります。
特に学習率が高すぎる場合に起こりやすいとされています。
Dead ReLU問題を改善する「Leaky ReLU」
Dead ReLU問題を改善するために考案されたのが「Leaky ReLU」です。
Leaky ReLUでは、負の領域でもわずかな傾きを持たせます。
一般的には以下のような形で表されます。
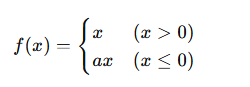
ここでの「a」は非常に小さな値(例:0.01)です。
これにより、
- 負の入力でも勾配が0にならない
- ニューロンが完全に停止しにくい
- 学習が安定しやすい
というメリットがあります。
現在では、用途に応じて以下のような派生手法も利用されています。
- Leaky ReLU
- Parametric ReLU(PReLU)
- ELU
- GELU
特にTransformer系モデルでは、GELUが採用されるケースも増えています。
ReLU関数はどんな場面で使われる?
ReLU関数は、現在の多くのディープラーニングモデルで標準的に利用されています。
代表例としては以下があります。
画像認識
- 顔認識
- 物体検出
- 医療画像解析
音声認識
- 音声アシスタント
- 自動字幕生成
自然言語処理
- 文章分類
- 感情分析
- チャットボット
特にCNNでは、ReLUが事実上の標準となっています。
シグモイド関数との違い
| 項目 | ReLU | シグモイド |
|---|---|---|
| 計算速度 | 高速 | やや遅い |
| 勾配消失 | 起こりにくい | 起こりやすい |
| 出力範囲 | 0〜∞ | 0〜1 |
| 深層学習との相性 | 良い | あまり良くない |
現在の深層学習では、隠れ層にはReLU系関数を使うケースが一般的です。
まとめ
ReLU関数は、現代のディープラーニングを支える重要な活性化関数です。
特徴を整理すると、以下のようになります。
- シンプルで計算が高速
- 勾配消失問題を軽減できる
- 深いニューラルネットワークでも学習しやすい
- CNNをはじめ多くのAIモデルで利用されている
一方で、「Dead ReLU問題」という課題も存在しますが、Leaky ReLUなどの改良版によって改善が進んでいます。
AI・機械学習を学ぶうえで、ReLU関数は基礎かつ重要な知識です。
活性化関数の役割を理解することで、ニューラルネットワークの仕組みをより深く理解できるようになるでしょう。
こちらもご覧ください:tanh関数とは?シグモイドとの違いやニューラルネットワークでの役割をわかりやすく解説


