
**SVM(Support Vector Machine)**は、分類や回帰問題に適用可能な強力な機械学習モデルの一つです。
本記事では、SVMの基本概念、動作原理、利点や課題について詳しく解説します。
SVMを理解することは、データ分析や機械学習の分野での技術的スキルを向上させるために非常に重要です。
SVMの基本概念
1. SVMの定義
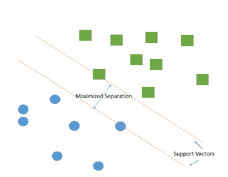
SVMは、データを2つのクラスに分けるための超平面を見つける手法です。
この超平面は、2次元の場合には直線となります。
SVMは、各データ点から最も離れた位置にある超平面を決定し、データを分離します。
これを実現するためには、最も近いデータ点、つまり「サポートベクター」の距離を計算し、マージンを最大化します。
2. 動作原理
SVMは、2次元のデータ群を直線で分けるだけでなく、次元を拡張して多次元空間での分割も可能です。
以下のステップで動作します。
- データの準備: 2つの特徴量で表されるデータを用意します。
- 超平面の決定: 直線(または超平面)の候補を作成し、サポートベクターからの距離を算出します。
- マージンの最大化: サポートベクターからの距離が最大になる超平面を選択します。
この過程において、カーネル関数を利用することで、線形分離が難しい非線形の分類問題にも対応できます。
SVMの利点と課題
1. SVMの利点
- 高い精度: 少ないデータでも高い識別精度を持つモデルを生成できます。
- 次元の増加に強い: 特徴量の数が増えても、識別精度を維持しやすいです。
- パラメータ調整が容易: 学習率やC値などの調整が比較的簡単です。
2. SVMの課題
- 計算量の増加: 学習データが増えると、計算量が急激に増加します。
- 多クラス分類への適用: 原理上、2クラス分類に特化しているため、多クラス分類には工夫が必要です。
- カーネル処理の負担: カーネル関数の処理が重くなる場合があります。
具体例と応用
例えば、スパムメールの分類にSVMを適用することができます。
この場合、メールの特徴(単語の頻度や送信者の情報など)を特徴量として用い、スパムと非スパムを分類するためのモデルを構築します。
このように、SVMは多様なデータセットに対して有効な手法として広く利用されています。
まとめ
**SVM(サポートベクターマシン)**は、機械学習において非常に有用な分類手法です。
その高い精度や次元の増加に対する適応力は、データ分析の現場での信頼性を高めます。
ただし、計算量の増大や多クラス分類への課題も存在するため、適切な使用法を理解することが求められます。SVMを駆使することで、データの洞察を深め、より良い意思決定をサポートすることが可能になります。
さらに参考してください。
サポートユーティリティとは?情報システム運用に不可欠な要素
Rate this post
Visited 8 times, 1 visit(s) today
