
半角文字(halfwidth characters)は、コンピュータにおける文字処理や表示に深く関わる基本的な概念です。
プログラミング、Web開発、データ処理などの現場で、全角文字との違いや混在による不具合に悩まされた経験のある技術者も多いのではないでしょうか。
本記事では、半角文字の定義から歴史、具体的な用途や全角文字との違い、システム開発時の注意点までを、IT専門の視点で詳しく解説します。
半角文字とは何か?
半角文字の基本定義
半角文字とは、等幅フォントで表示・印刷されたときに、縦長の長方形(全角の半分の幅)に収まるように設計された文字です。
ASCIIやその拡張規格に含まれる文字が多く、以下のようなものが該当します。
-
英字:A〜Z、a〜z
-
数字:0〜9
-
記号:@ # $ % & * – _ . , など
対比される「全角文字」とは?
全角文字は、正方形の領域に収まるように設計された文字で、日本語のひらがな・カタカナ・漢字・句読点などが代表的です。
例:
-
全角文字:「漢」「ア」「。」「、」
-
半角文字:「A」「a」「1」「.」
半角文字の歴史と文字コードとの関係
ASCIIと1バイト文字
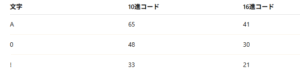
半角英数字は主にASCII(American Standard Code for Information Interchange)に由来し、1文字あたり1バイト(8ビット未満)で表現される1バイト文字です。
ASCIIでは、以下のように割り当てられています:
半角カタカナとJIS拡張
日本独自のASCII拡張仕様であるJIS X 0201では、「ア」「カ」「。」「エ゙」などの半角カタカナが定義されました。
これにより、ASCIIと互換性を保ちながらも、簡易的な日本語表記が可能となりました。
Unicodeにも、これらの文字は「HALFWIDTH KATAKANA」というカテゴリで収録されています。
半角文字の用途と実例
プログラミングにおける使用例
プログラム中では、半角文字で記述されることが基本です。
以下に主な用途を挙げます:
1. ソースコード
変数名、関数名、キーワード、演算子などはすべて半角で記述されます。

2. ファイル名・パス名
多くのOSでは、半角文字を使用することで互換性が高く、文字化けのリスクも低減できます。
![]()
3. データベースやCSV
CSV形式のデータでは、カンマ(,)やドット(.)といった半角記号が区切り文字として使用されます。
![]()
ユーザーインターフェースにおける注意点
Webフォームやアプリケーション入力欄では、ユーザーが全角で入力した場合のバリデーション処理が必要です。
-
NG: ABC123(全角)
-
OK: ABC123(半角)
この違いを無視すると、認証エラーや検索ヒットしないといったUX上のトラブルを招くことがあります。
全角文字との違いと混在の影響
見た目の違い
等幅フォントでは、半角1文字 = 全角の約1/2の幅で表示されます。
これにより、文字列の整列やデータの表示形式に影響を及ぼします。
システム処理への影響
-
文字数カウントの誤差
-
半角10文字:10バイト
-
全角10文字:20バイト(UTF-8なら最大30バイト)
-
-
正規表現の誤判定
-
/[A-Za-z]/は半角英字のみを対象にするため、「A」はマッチしない。
-
実務上のトラブル事例
-
ユーザーIDの照合ミス
-
DB:
Taro123(半角) -
入力:
Taro123(全角)
-
-
ログファイルの読み取り不能
-
ログ中に混在した半角・全角文字列があり、文字コード誤解釈により読み込みエラー発生。
-
プロポーショナルフォントと現代の文字幅
現代のシステムやブラウザでは、プロポーショナルフォント(文字ごとに幅が異なる)が一般的です。
そのため、「半角=半分の幅」という前提が成立しないケースも多くなってきています。
ただし、ターミナルやコードエディターではモノスペースフォント(等幅フォント)が使用されるため、依然として半角文字と全角文字の違いは重要です。
まとめ
半角文字は、IT業界においてあらゆるシステムやアプリケーションで基礎となる重要な概念です。
ASCIIを起点とした歴史的背景と、全角文字との厳密な違いを理解することで、開発上のトラブルやユーザビリティの低下を防ぐことができます。
覚えておくべきポイント:
-
半角文字=等幅フォントで幅が半分
-
ASCIIやJIS X 0201に基づく1バイト文字
-
全角文字との混在はバグの原因になり得る
-
入力バリデーション・文字列比較では特に注意が必要
今後も国際化や多言語対応が進む中で、文字種の理解はより一層重要になります。
システム設計やアプリ開発において、半角文字の適切な扱いを心がけましょう。