

ディープラーニングは、画像認識や自然言語処理、生成AIなどで高い性能を発揮しています。
しかし、ニューラルネットワークを深くすればするほど、学習がうまく進まなくなる問題がありました。
その代表的な問題が「勾配消失問題(Vanishing Gradient Problem)」です。
勾配消失問題が発生すると、ネットワークの前半部分がほとんど学習できなくなり、深層学習の性能が大きく低下します。
実際、現在のディープラーニング技術が発展する以前、多層ニューラルネットワークの学習は非常に困難でした。
その壁を突破する上で、勾配消失問題の理解と対策は極めて重要でした。
本記事では、勾配消失問題の仕組みや原因、シグモイド関数との関係、ReLUやResNetによる解決策までをわかりやすく解説します。
勾配消失問題とは?
勾配消失問題(Vanishing Gradient Problem)とは、ニューラルネットワークの学習中に、誤差情報を伝える「勾配」が極端に小さくなり、前半の層が学習できなくなる現象です。
簡単に言えば、「深いネットワークの初期層に学習信号が届かなくなる問題」です。
勾配とは何か?
ニューラルネットワークでは、予測結果と正解との差を小さくするために、重み(パラメータ)を更新します。
その更新方向を決めるのが「勾配(Gradient)」です。
勾配降下法の基本イメージ
勾配降下法では、誤差を減らす方向へ少しずつパラメータを更新します。

誤差逆伝播法(バックプロパゲーション)とは?
ニューラルネットワークでは、「誤差逆伝播法(Backpropagation)」によって学習を行います。
これは、出力層で計算した誤差を逆方向へ伝播し、各層の重みを更新する仕組みです。
勾配はどう伝わる?
勾配は、出力層から入力層へ向かって順番に伝わります。
その際、各層で、
- 重み
- 活性化関数の微分値
が掛け合わされます。
勾配消失問題が起きる理由
問題は、「小さな値を何度も掛け算する」点にあります。
連鎖律(Chain Rule)の影響
バックプロパゲーションでは、微分の連鎖律が使われます。
簡単に言えば、各層の微分値を掛け合わせながら伝播していきます。
数式イメージ
勾配は以下のように連続的に掛け算されます。

と掛け算され、急激に小さくなります。
シグモイド関数が原因になった理由
初期のディープラーニングでは、
- シグモイド関数
- tanh関数
がよく使われていました。
シグモイド関数の特徴
シグモイド関数は滑らかですが、入力値が極端に大きい・小さい領域では、微分値が非常に小さくなります。
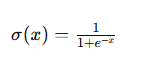
飽和領域とは?
入力値が大きくなると、シグモイド関数の出力は、
- ほぼ0
- ほぼ1
に張り付きます。
この状態を「飽和領域」と呼びます。
飽和領域では勾配が小さい
飽和領域では微分値がほぼ0になります。
その結果、
- 勾配が伝わらない
- 前半層が更新されない
問題が発生します。
何が問題なのか?
勾配がほぼゼロになると、重み更新量もほぼゼロになります。
つまり、「学習が止まる」状態になります。
深いネットワークほど悪化する
浅いネットワークでは問題が小さいですが、層が深くなるほど悪化します。
そのため、初期の深層学習は非常に困難でした。
勾配消失問題の影響
初期層が学習できない
画像認識では、初期層は、
- エッジ
- 輪郭
- 模様
など基本特徴を学習します。
しかし勾配が届かないと、それらが十分学習できません。
学習速度低下
ネットワーク全体の収束が遅くなります。
精度低下
深いモデルなのに性能が出ない原因になります。
現在はどう解決している?
現在のディープラーニングでは、多くの解決策が導入されています。
ReLU関数の利用
最も重要な解決策の一つが「ReLU」です。
![]()
ReLUのメリット
ReLUは正の領域で勾配が一定です。
そのため、
- 勾配が消えにくい
- 深いネットワークでも学習しやすい
特徴があります。
重み初期化の工夫
初期値設定も重要です。
代表例には、
- Xavier初期化
- He初期化
があります。
適切な初期化により、勾配の極端な縮小を防ぎます。
バッチ正規化(Batch Normalization)
Batch Normalizationは、各層のデータ分布を安定化する技術です。
これにより、
- 勾配伝播
- 学習安定性
が改善されます。
ResNet(残差ネットワーク)
現在の深層学習を大きく進歩させた技術の一つです。
スキップ接続とは?
ResNetでは、入力を後段へ直接渡す「スキップ接続」を導入します。
![]()
これにより、
- 勾配が直接伝わる
- 超深層ネットワークが可能
になりました。
LSTM・GRUによる対策
RNN系では、
- LSTM
- GRU
が勾配消失対策として開発されました。
これにより長期依存関係を扱いやすくなりました。
Transformer時代では?
現在主流のTransformerでも、
- ReLU系活性化関数
- Layer Normalization
- Residual Connection
などが利用され、勾配消失問題への対策が組み込まれています。
ChatGPTのような大規模言語モデル(LLM)でも重要です。
勾配爆発問題との違い
勾配消失と対になる問題として、勾配爆発問題(Exploding Gradient)もあります。
これは逆に、勾配が大きくなりすぎる現象です。
まとめ
勾配消失問題(Vanishing Gradient Problem)とは、バックプロパゲーション中に勾配が極端に小さくなり、前半層が学習できなくなる問題です。
特に、
- シグモイド関数
- tanh関数
- 深いネットワーク
で発生しやすい特徴があります。
現在では、
- ReLU
- Batch Normalization
- ResNet
- LSTM
- 適切な初期化
など多くの技術によって改善されています。
勾配消失問題の克服は、現代ディープラーニング発展の大きな転換点であり、現在の生成AIや大規模言語モデルの基盤を支える重要技術の一つです。
こちらもご覧ください:活性化関数とは?ニューラルネットワークで“非線形性”を生み出す重要技術をわかりやすく解説


