

機械学習やディープラーニングでは、AIモデルが「どれだけ間違っているか」を数値で評価しながら学習を進めています。
そのときに使われる重要な仕組みが「誤差関数(Error Function)」です。
誤差関数は「損失関数(Loss Function)」とも呼ばれ、AIモデルの性能を改善するための中心的な役割を担っています。
AIは、誤差関数によって算出された「間違いの大きさ」をもとに、自動的にパラメータを調整しながら精度を高めていきます。
本記事では、誤差関数の基本概念から代表的な種類、機械学習での役割、実務での重要性までをわかりやすく解説します。
誤差関数とは?
誤差関数とは、AIモデルの予測結果と正解データとの差を数値化する関数です。
機械学習では、まず入力データをモデルへ与え、予測結果を出力します。
その後、実際の正解データと比較し、「どれくらいズレているか」を計算します。
このズレを表現するのが誤差関数です。
誤差関数のイメージ
たとえば、住宅価格を予測するAIを考えてみましょう。
- 実際の価格:3,000万円
- AIの予測:2,700万円
この場合、300万円の誤差があります。
誤差関数は、この「予測と正解の差」を計算し、AIへフィードバックします。
そしてAIは、
- 「どのパラメータを修正すればよいか」
- 「どの方向へ学習を進めるべきか」
を判断しながら、徐々に精度を高めていきます。
なぜ誤差関数が重要なのか?
AI学習の“目的地”になる
誤差関数は、AI学習における「目標」の役割を持っています。
機械学習では基本的に、
- 誤差をできるだけ小さくする
- 損失を最小化する
方向へ学習を進めます。
つまり、AIは「誤差関数を小さくするゲーム」を繰り返しているとも言えます。
モデル性能を数値で評価できる
誤差関数によって、モデルの性能を定量的に評価できます。
たとえば、
- 誤差が小さい → 高精度
- 誤差が大きい → 低精度
と判断できます。
この仕組みによって、学習の進み具合を客観的に確認できます。
誤差関数の代表的な種類
機械学習では、解決したい問題に応じて異なる誤差関数を使います。
回帰問題で使われる誤差関数
平均二乗誤差(MSE)
回帰問題で最もよく使われる誤差関数が「平均二乗誤差(Mean Squared Error)」です。
MSEは、
- 予測値と正解値の差
- その差を二乗
- 全体平均を計算
することで誤差を求めます。
MSEの特徴
大きな誤差を強く評価する
差を二乗するため、大きなミスほど強くペナルティが与えられます。
たとえば、
- 誤差1 → 1
- 誤差10 → 100
となるため、大きなズレを重点的に改善できます。
MSEの活用例
MSEは以下のような回帰タスクで利用されます。
- 株価予測
- 売上予測
- 気温予測
- 不動産価格予測
など、連続値を扱う問題に適しています。
RMSE(平方根平均二乗誤差)
MSEの派生として「RMSE(Root Mean Squared Error)」もよく使われます。
RMSEは、MSEの平方根を取ったものです。
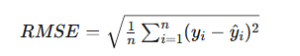
MSEよりも元データと同じ単位で解釈できるため、実務で扱いやすい特徴があります。
分類問題で使われる誤差関数
交差エントロピー誤差(Cross Entropy Error)
画像認識や自然言語処理などの分類問題では、「交差エントロピー誤差」が標準的に使われます。
これは、モデルが出力した確率分布と、正解データとのズレを測定する誤差関数です。
なぜ分類問題に適しているのか?
分類問題では、「どのクラスが正しいか」を確率として出力します。
たとえば猫画像認識なら、
- 猫:90%
- 犬:5%
- 鳥:5%
のような形です。
交差エントロピー誤差は、
- 正解クラスの確率を高くする
- 不正解クラスの確率を低くする
ように学習を促します。
AIが“確信度”を学習する
単に正解・不正解を見るだけではなく、どれくらい自信を持って予測したかまで考慮できる点が大きな特徴です。
そのため、ディープラーニングでは非常に重要な誤差関数となっています。
誤差関数と勾配降下法の関係
機械学習では、誤差関数を小さくするために「最適化」が行われます。
その代表的な手法が「勾配降下法(Gradient Descent)」です。
勾配降下法とは?
勾配降下法は、誤差関数の傾きを計算し、
- 誤差が減る方向
- 最も効率よく改善できる方向
へ少しずつパラメータを更新していく手法です。
イメージとしては、
- 山の斜面を下る
- 一番低い地点を探す
ような動きに近いです。
微分可能であることが重要
多くの最適化アルゴリズムでは、誤差関数の「微分」が必要になります。
そのため、機械学習で使われる誤差関数は、基本的に微分可能な形で設計されています。
誤差関数選びはモデル性能に直結する
誤差関数は単なる計算式ではありません。
どの誤差関数を選ぶかによって、
- 学習速度
- 予測精度
- 安定性
- 外れ値への強さ
などが大きく変化します。
たとえば外れ値が多い場合
MSEは大きな誤差に敏感なため、外れ値の影響を強く受けます。
そのため実務では、
- MAE(平均絶対誤差)
- Huber Loss
など、別の誤差関数が選ばれることもあります。
ディープラーニングでの誤差関数の重要性
近年の生成AIや大規模言語モデル(LLM)でも、誤差関数は中核技術です。
たとえば、
- 次単語予測
- 画像生成
- 音声認識
- 翻訳AI
など、あらゆるAI学習に誤差関数が利用されています。
AIの進化は、「どれだけ適切に誤差を定義できるか」に大きく依存しているとも言えます。
まとめ
誤差関数(損失関数)とは、AIモデルの予測結果と正解とのズレを数値化する仕組みです。
機械学習では、この誤差を小さくする方向へ学習が進められます。
代表的な誤差関数には、
- 平均二乗誤差(MSE)
- RMSE
- 交差エントロピー誤差
などがあります。
また、誤差関数は勾配降下法などの最適化手法と密接に関係しており、AI学習の根幹を支える存在です。
適切な誤差関数を選択することは、AIモデルの性能や実用性を大きく左右する重要なポイントとなっています。
こちらもご覧ください:データリーケージ(Data Leakage)とは?AIモデルの精度を誤認させる原因をわかりやすく解説


