

機械学習やディープラーニングでは、モデルの精度を高めるために「最適化アルゴリズム」が重要な役割を果たします。
その中でも、学習率を自動調整しながら安定した学習を実現する手法として広く利用されているのが「RMSprop(Root Mean Square Propagation)」です。
RMSpropは、AdaGradの弱点を改善する形で登場したアルゴリズムであり、現在でも深層学習や強化学習など幅広い分野で利用されています。
この記事では、RMSpropの仕組みや特徴、AdaGradとの違い、メリット・デメリットまで初心者にも分かりやすく解説します。
RMSpropとは
RMSprop(Root Mean Square Propagation)とは、機械学習における最適化アルゴリズムの一種です。
勾配降下法をベースにしながら、パラメータごとに学習率を自動調整する特徴があります。
特に、過去の勾配情報を「指数移動平均」で管理することで、学習率が極端に小さくなりすぎる問題を改善しています。
現在では、
- ディープラーニング
- 強化学習
- RNN(再帰型ニューラルネットワーク)
などで広く使われています。
勾配降下法の基本
まずは、RMSpropのベースとなる勾配降下法を簡単に確認しておきましょう。
勾配降下法(Gradient Descent)は、損失関数を最小化する方向へ少しずつパラメータを更新する手法です。
基本式は以下の通りです。
![]()
ここで使われる主な記号は以下の通りです。
- θ:モデルのパラメータ
- η:学習率
- ∇J:勾配(変化量)
しかし通常の勾配降下法では、すべてのパラメータに同じ学習率を適用するため、効率的に学習できない場合があります。
AdaGradの問題点
RMSpropを理解するには、前身となるAdaGradについて知る必要があります。
AdaGradでは、過去の勾配の二乗和を累積し、それに応じて学習率を調整します。
これにより、
- 更新頻度が高いパラメータ → 小さく更新
- 更新頻度が低いパラメータ → 大きく更新
が可能になりました。
しかしAdaGradには大きな欠点があります。
それは、勾配の累積値が増え続けることで、学習率がどんどん小さくなってしまう点です。
結果として、
- 学習後半で更新が止まる
- 学習速度が極端に低下する
という問題が発生しました。
RMSpropの仕組み
RMSpropは、このAdaGradの問題を改善するために考案されました。
最大の特徴は、「古い勾配情報を徐々に忘れる」ことです。
具体的には、勾配の二乗平均を指数移動平均(Exponential Moving Average)で計算します。
更新式は以下のようになります。
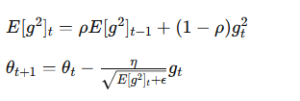
ここで重要なのが以下の要素です。
- ρ(ロー):減衰率
- ε(イプシロン):ゼロ除算防止用の微小値
古い勾配ほど影響を弱めることで、学習率が必要以上に小さくなるのを防いでいます。
RMSpropの特徴
学習率を自動調整できる
RMSpropでは、勾配の変化に応じてパラメータごとの学習率を動的に調整できます。
これにより、学習の安定性が向上します。
非定常な問題に強い
RMSpropは、途中で勾配特性が変化する「非定常環境」に強い特徴があります。
例えば以下の分野で効果を発揮します。
- 強化学習
- 時系列予測
- 音声認識
環境変化に柔軟に対応できる点が大きな利点です。
RNNとの相性が良い
RNN(再帰型ニューラルネットワーク)は、時系列データを扱う際に使われます。
しかしRNNでは、
- 勾配消失
- 学習不安定化
が発生しやすい問題があります。
RMSpropは勾配変動を安定化しやすいため、RNN学習との相性が良いとされています。
RMSpropのメリット
学習が安定しやすい
指数移動平均を利用することで、急激な更新変化を抑制できます。
AdaGradより長期学習に強い
学習率が単調減少しないため、長時間の学習でも更新が止まりにくくなります。
ハイパーパラメータ調整が比較的容易
自動調整機能があるため、細かな学習率チューニングの負担を減らせます。
RMSpropのデメリット
パラメータ設定が必要
減衰率ρなどの設定次第で性能が変わります。
一般的には以下がよく使われます。
- 学習率:0.001
- 減衰率ρ:0.9
理論的保証が少ない
実用性は高い一方で、理論的解析が難しい部分もあります。
そのため、問題によっては他手法の方が適する場合もあります。
Adamとの関係
現在の深層学習では、「Adam」が最も広く利用される最適化アルゴリズムの一つです。
Adamは、以下2つを組み合わせた手法です。
- Momentum(運動量)
- RMSprop(適応的学習率)
つまりRMSpropは、Adamの基礎技術の一つともいえます。
RMSpropが活用される分野
RMSpropは、さまざまなAI分野で利用されています。
代表例は以下の通りです。
- 強化学習
- 自然言語処理(NLP)
- 音声認識
- 時系列予測
- RNN / LSTM
- 深層学習全般
特に、勾配変化が激しいタスクで効果を発揮します。
他の最適化アルゴリズムとの比較
| 手法 | 特徴 |
|---|---|
| SGD | シンプルな勾配降下法 |
| Momentum | 慣性を利用 |
| AdaGrad | 学習率を自動調整 |
| RMSprop | AdaGradを改良 |
| Adam | Momentum + RMSprop |
RMSpropは、「安定性」と「適応的学習率」のバランスが優れたアルゴリズムとして位置づけられます。
まとめ
RMSprop(Root Mean Square Propagation)は、AdaGradの欠点を改善した最適化アルゴリズムです。
過去の勾配を指数移動平均で管理することで、
- 学習率の極端な低下を防ぐ
- 安定した学習を実現する
- 非定常環境に対応しやすい
といったメリットがあります。
現在でも、
- 強化学習
- RNN
- ディープラーニング
など多くの分野で重要な役割を果たしています。
さらに、現在主流のAdamアルゴリズムの基礎技術にもなっており、機械学習を学ぶうえで理解しておきたい重要な最適化手法の一つです。
こちらもご覧ください:AdaGradとは?機械学習の学習率を自動調整する最適化アルゴリズムをわかりやすく解説


