

機械学習やディープラーニングでは、AIモデルの性能を高めるために「最適化アルゴリズム」が重要な役割を果たします。
その中でも、学習率を自動的に調整できる手法として知られているのが「AdaGrad(Adaptive Gradient)」です。
AdaGradは、特徴量ごとに異なる学習率を適用することで、効率的な学習を実現するアルゴリズムとして広く注目されました。
特に自然言語処理(NLP)の分野で高い効果を発揮することで知られています。
この記事では、AdaGradの仕組みやメリット・デメリット、勾配降下法との違い、実際の活用シーンまで分かりやすく解説します。
AdaGradとは
AdaGrad(Adaptive Gradient)とは、機械学習における最適化アルゴリズムの一種です。
通常の勾配降下法では、すべてのパラメータに同じ学習率を適用します。
しかしAdaGradでは、パラメータごとに異なる学習率を自動調整します。
これにより、
- 更新頻度が高いパラメータは小さく更新
- 更新頻度が低いパラメータは大きく更新
という制御が可能になります。
特に、データの出現頻度に偏りがある場合に効果を発揮します。
勾配降下法の基本
AdaGradを理解する前に、まずは勾配降下法(Gradient Descent)の基本を確認しておきましょう。
勾配降下法は、損失関数を最小化する方向へ少しずつパラメータを更新する手法です。
基本的な更新式は以下の通りです。
![]()
ここで使われる主な記号は以下の通りです。
- θ:モデルのパラメータ
- η:学習率
- ∇J:勾配(変化量)
ただし通常の勾配降下法には、すべてのパラメータに同じ学習率を適用するという課題があります。
そのため、
- 一部だけ更新が大きすぎる
- 更新が進みにくい特徴量がある
- 最適な学習率調整が難しい
といった問題が発生します。
AdaGradの仕組み
AdaGradでは、過去の勾配情報を蓄積しながら学習率を調整します。
特徴的なのは、「勾配の二乗和」を利用する点です。
基本的な更新式は以下のようになります。
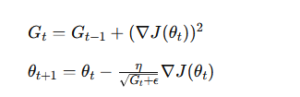
この仕組みにより、
- 勾配が大きいパラメータ → 学習率が小さくなる
- 勾配が小さいパラメータ → 学習率が比較的大きく保たれる
という調整が自動で行われます。
AdaGradが注目された理由
学習率を自動調整できる
従来の機械学習では、適切な学習率を人間が試行錯誤しながら設定する必要がありました。
しかしAdaGradでは、学習の進行状況に応じて自動調整されるため、チューニング負担を減らせます。
疎なデータに強い
AdaGradは、出現頻度が少ない特徴量にも適切な更新を行えます。
これは「疎(Sparse)データ」と呼ばれるデータ構造で特に有効です。
例えば自然言語処理では、
- 単語数が非常に多い
- 一部の単語しか登場しない
といった特徴があります。
AdaGradは、このような高次元データでも効率的に学習できます。
自然言語処理との相性が良い
AdaGradは、以下のようなNLPタスクで広く利用されてきました。
- 機械翻訳
- 文書分類
- 単語埋め込み
- 検索エンジン
- チャットボット
特に、頻出単語と希少単語の差が大きい環境で効果を発揮します。
AdaGradのメリット
ハイパーパラメータ調整が少ない
学習率調整を自動化できるため、初心者でも扱いやすい特徴があります。
安定した学習が可能
勾配の大きい方向で更新を抑制できるため、急激な発散を防ぎやすくなります。
特徴量ごとに最適化できる
各パラメータに異なる学習率を適用できるため、効率的な最適化が可能です。
AdaGradのデメリット
学習率が小さくなりすぎる
AdaGrad最大の弱点は、勾配の累積値が増え続ける点です。
学習が進むほど分母が大きくなり、最終的には学習率が極端に小さくなる場合があります。
その結果、
- 更新がほとんど止まる
- 学習が進まなくなる
といった問題が発生します。
長期学習に向かない場合がある
深層学習のような大規模モデルでは、後半になると学習速度が大きく低下することがあります。
そのため、現在ではAdaGrad単体よりも改良版アルゴリズムが多く利用されています。
AdaGradから発展した代表的手法
AdaGradの弱点を改善するため、さまざまな派生アルゴリズムが登場しました。
代表例は以下の通りです。
| 手法 | 特徴 |
|---|---|
| RMSprop | 古い勾配の影響を減衰 |
| Adam | Momentum + RMSprop を組み合わせ |
| AdaDelta | 学習率低下問題を改善 |
特にAdamは現在の深層学習で最も広く利用される最適化手法の一つです。
AdaGradと他の最適化手法の違い
| 手法 | 特徴 |
|---|---|
| SGD | シンプルな勾配降下法 |
| Momentum | 慣性を利用して加速 |
| AdaGrad | 学習率を自動調整 |
| RMSprop | AdaGradの改良版 |
| Adam | MomentumとAdaGrad系を融合 |
AdaGradは、「パラメータごとに学習率を変える」という考え方を広めた重要なアルゴリズムです。
実務でのAdaGradの活用例
AdaGradは、以下のような分野で利用されてきました。
- 自然言語処理(NLP)
- レコメンドシステム
- テキスト解析
- 広告配信システム
- 検索ランキング
特に大量の特徴量を扱うシステムで効果があります。
まとめ
AdaGrad(Adaptive Gradient)は、パラメータごとに学習率を自動調整する最適化アルゴリズムです。
特に、
- 疎なデータに強い
- 学習率調整が容易
- 自然言語処理と相性が良い
といった特徴から、多くの機械学習分野で活用されてきました。
一方で、学習率が小さくなりすぎる問題もあり、現在ではRMSpropやAdamなどの改良版が主流になっています。
それでもAdaGradは、「適応的学習率」という重要な考え方を生み出した、機械学習史において非常に重要なアルゴリズムです。
こちらもご覧ください:モーメンタム(Momentum)とは?機械学習の学習効率を高める最適化手法をわかりやすく解説


