

機械学習やディープラーニングでは、「AIが予測した分布」と「実際のデータ分布」がどれくらい近いかを評価することが重要です。
その際によく使われる代表的な指標が「KLダイバージェンス(Kullback–Leibler divergence)」です。
KLダイバージェンスは、日本語では「カルバック・ライブラー情報量」とも呼ばれ、確率分布同士の違いを数値化するために利用されます。
特に、
- 生成AI
- ベイズ推定
- 自己教師あり学習
- 変分オートエンコーダ(VAE)
など、現代AIの重要技術で広く活用されています。
本記事では、KLダイバージェンスの基本概念から、交差エントロピーとの関係、非対称性の意味、実際の活用例までをわかりやすく解説します。
KLダイバージェンスとは?
KLダイバージェンスとは、2つの確率分布の違いを測定する指標です。
具体的には、
- 真の分布 PP
- 近似分布 QQ
の間にどれくらいズレがあるかを数値化します。
直感的なイメージ
たとえば、
- 実際のデータ分布
- AIモデルが予測した分布
を比較する場面を考えます。
もし両者が非常に似ていれば、KLダイバージェンスは小さくなります。
逆に、大きく異なっていれば値は大きくなります。
つまり、「AIの予測分布が、本物のデータ分布にどれくらい近いか」を評価するための指標と言えます。
KLダイバージェンスの数式
KLダイバージェンスは、以下の式で表されます。

を表します。
KLダイバージェンスが0になる条件
KLダイバージェンスは、2つの分布が完全に一致した場合に0になります。
つまり、
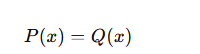
であれば、両者に差がないことを意味します。
一方、分布が異なるほど値は大きくなります。
なぜ「距離」ではなく「ダイバージェンス」なのか?
KLダイバージェンスは、よく「分布間の距離」と説明されます。
しかし、数学的には通常の距離とは少し異なります。
その理由は、「非対称性」があるためです。
KLダイバージェンスの非対称性
KLダイバージェンスには、以下の特徴があります。
![]()
つまり、
- Pから見たQ
- Qから見たP
では値が異なる場合があります。
なぜ非対称になるのか?
KLダイバージェンスでは、
- どちらを「真の分布」とみなすか
- どちらを「近似分布」とみなすか
によって意味が変わります。
これは単なる距離計算ではなく、「情報損失」を測定しているためです。
交差エントロピーとの関係
KLダイバージェンスは、交差エントロピーと深い関係があります。
以下の関係式で表されます。

です。
何を意味している?
これは、「交差エントロピー = 本来必要な情報量 + 分布のズレ」であることを意味します。
そのため、分類AIでは交差エントロピー最小化が、実質的にKLダイバージェンス最小化につながるケースも多くあります。
深層学習でのKLダイバージェンスの役割
KLダイバージェンスは、現代AIで非常に重要な役割を担っています。
生成AIでの利用
生成モデルでは、
- 本物データの分布
- AIが生成したデータ分布
を近づける必要があります。
その際、KLダイバージェンスを最小化することで、「本物らしいデータ生成」を目指します。
変分オートエンコーダ(VAE)
KLダイバージェンスが特に有名なのが「VAE(Variational Autoencoder)」です。
VAEでは、
- 潜在空間の分布
- 正規分布
の差をKLダイバージェンスで制御します。
これにより、滑らかで意味のある潜在表現を学習できます。
ベイズ推定での活用
統計学やベイズ推定でも重要です。
たとえば、
- 事前分布
- 事後分布
の違いを評価する際に利用されます。
不確実性を扱うAIモデルでは欠かせない概念です。
自然言語処理(NLP)での利用
近年の大規模言語モデル(LLM)でも利用されています。
たとえば、
- 出力分布の比較
- 蒸留学習(Knowledge Distillation)
- 強化学習
などで重要な役割を果たします。
KLダイバージェンスのメリット
分布全体を比較できる
単純な誤差ではなく、
- 確率構造
- 分布の形状
まで考慮できます。
これは生成AIで特に重要です。
確率モデルとの相性が良い
KLダイバージェンスは確率論ベースのため、
- ベイズモデル
- 生成モデル
- 自己教師あり学習
などとの親和性が非常に高い特徴があります。
KLダイバージェンスの注意点
非対称性がある
前述の通り、
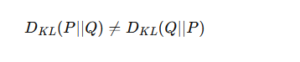
です。
そのため、どちらを基準にするかを慎重に設計する必要があります。
ゼロ確率問題
![]()
対数計算が発散してしまいます。
そのため実装では、
- スムージング
- 数値安定化
などの工夫が必要です。
Jensen-Shannon Divergenceとの違い
KLダイバージェンスの欠点を補うために、「Jensen-Shannon Divergence(JSダイバージェンス)」もよく利用されます。
JSダイバージェンスは、
- 対称性がある
- 値が安定しやすい
という特徴があります。
GAN(敵対的生成ネットワーク)などでも重要です。
まとめ
KLダイバージェンス(カルバック・ライブラー情報量)とは、2つの確率分布の違いを測定する指標です。
主に、
- 生成AI
- ベイズ推定
- 深層学習
- 自然言語処理
- VAE
などで広く利用されています。
また、
- 分布全体を比較できる
- 確率モデルと相性が良い
という強みを持つ一方で、
- 非対称性
- ゼロ確率問題
などの注意点もあります。
現代AIでは、「単なる正解率」だけでなく、「データ分布そのもの」を学習する重要性が高まっており、KLダイバージェンスはその中心的な役割を担う技術の一つとなっています。
こちらもご覧ください:交差エントロピー(Cross Entropy)とは?機械学習で重要な損失関数をわかりやすく解説


